통계 정보 갱신
테이블과 인덱스에 대한 통계 정보는 데이터베이스 시스템이 질의를 효과적으로 처리할 수 있게 한다. 통계 정보는 인덱스의 생성, 테이블의 생성등 DDL 문과 INSERT, DELETE 등 DML 문에 대해서 자동으로 갱신되지 않는다. UPDATE STATISTICS 문만이 통계정보를 갱신하는 유일한 방법이다. 필요한 경우 사용자가 직접 UPDATE STATISTICS 문을 수행하여 통계 정보를 갱신해야 한다(통계 정보 확인 참고)
UPDATE STATISTICS 문은 주기적으로 수행할 것을 권장한다. 또한 새로운 인덱스가 추가되거나, 대량의 INSERT, 혹은 DELETE 문이 수행되어 실제 정보와 통계 정보 사이에 차이가 커질 때 수행할 것을 권장한다.
UPDATE STATISTICS ON class-name[, class-name, ...] [WITH FULLSCAN];
UPDATE STATISTICS ON ALL CLASSES [WITH FULLSCAN];
UPDATE STATISTICS ON CATALOG CLASSES [WITH FULLSCAN];
WITH FULLSCAN: 지정된 테이블의 전체 데이터를 가지고 통계 정보를 업데이트한다. 생략 시 샘플링한 데이터를 가지고 통계 정보를 업데이트한다. 데이터 샘플은 테이블 전체 페이지 수와 상관없이 7페이지이다.
참고
10.0 부터는 HA 환경의 마스터에서 수행한 UPDATE STATISTICS 문이 슬레이브/레플리카에 복제된다.
ALL CLASSES: 모든 테이블의 통계 정보를 업데이트한다.
CATALOG CLASSES: 카탈로그 테이블에 대한 통계 정보를 업데이트한다.
CREATE TABLE foo (a INT, b INT);
CREATE INDEX idx1 ON foo (a);
CREATE INDEX idx2 ON foo (b);
UPDATE STATISTICS ON foo;
UPDATE STATISTICS ON foo WITH FULLSCAN;
UPDATE STATISTICS ON ALL CLASSES;
UPDATE STATISTICS ON ALL CLASSES WITH FULLSCAN;
UPDATE STATISTICS ON CATALOG CLASSES;
UPDATE STATISTICS ON CATALOG CLASSES WITH FULLSCAN;
통계 정보 갱신 시작과 종료 시 서버 에러 로그에 NOTIFICATION 메시지를 출력하며, 이를 통해 통계 정보 갱신에 걸리는 시간을 확인할 수 있다.
Time: 05/07/13 15:06:25.052 - NOTIFICATION *** file ../../src/storage/statistics_sr.c, line 123 CODE = -1114 Tran = 1, CLIENT = testhost:csql(21060), EID = 4
Started to update statistics (class "code", oid : 0|522|3).
Time: 05/07/13 15:06:25.053 - NOTIFICATION *** file ../../src/storage/statistics_sr.c, line 330 CODE = -1115 Tran = 1, CLIENT = testhost:csql(21060), EID = 5
Finished to update statistics (class "code", oid : 0|522|3, error code : 0).
통계 정보 확인
CSQL 인터프리터의 세션 명령어로 지정한 테이블의 통계 정보를 확인한다.
csql> ;info stats table_name
table_name: 통계 정보를 확인할 테이블 이름
다음은 CSQL 인터프리터에서 t1 테이블의 통계 정보를 출력하는 예제이다.
CREATE TABLE t1 (code INT);
INSERT INTO t1 VALUES(1),(2),(3),(4),(5);
CREATE INDEX i_t1_code ON t1(code);
UPDATE STATISTICS ON t1;
;info stats t1
CLASS STATISTICS
****************
Class name: t1 Timestamp: Mon Mar 14 16:26:40 2011
Total pages in class heap: 1
Total objects: 5
Number of attributes: 1
Attribute: code
id: 0
Type: DB_TYPE_INTEGER
Minimum value: 1
Maximum value: 5
B+tree statistics:
BTID: { 0 , 1049 }
Cardinality: 5 (5) , Total pages: 2 , Leaf pages: 1 , Height: 2
질의 실행 계획 보기
CUBRID SQL 질의에 대한 실행 계획(query plan)을 보기 위해서는 다음의 방법을 사용할 수 있다.
CUBRID Manager에서 “플랜 보기” 버튼을 누른다.
CSQL 인터프리터에서 ;plan simple 또는 ;plan detail 명령을 실행하거나 SET OPTIMIZATION 구문을 이용해서 최적화 수준(optimization level) 값을 변경시킨다. 현재의 최적화 수준 값은 GET OPTIMIZATION 구문으로 얻을 수 있다. CSQL 인터프리터에 대한 자세한 내용은 세션 명령어를 참고한다.
SET OPTIMIZATION 또는 GET OPTIMIZATION LEVEL 구문은 다음과 같다.
SET OPTIMIZATION LEVEL opt-level [;]
GET OPTIMIZATION LEVEL [ { TO | INTO } variable ] [;]
opt-level : 최적화 수준을 지정하는 값으로 다음과 같은 의미를 갖는다.
0 : 질의 최적화를 수행하지 않는다. 실행하는 질의는 가장 단순한 형태의 실행 계획을 가지고 실행된다. 디버깅의 용도 이외에는 사용되지 않는다.
1 : 질의 최적화를 수행한다. CUBRID에서 사용되는 기본 설정 값으로 대부분의 경우 변경할 필요가 없다.
2: 질의 최적화를 수행하여 실행 계획을 생성하나 질의 자체는 수행되지 않는다. 일반적으로 사용되지 않고 다음 질의 실행 계획 보기를 위한 설정값과 같이 설정되어 사용된다.
257 : 질의 최적화를 수행하여 생성된 질의 실행 계획(플랜)을 출력한다. 256+1의 값으로 해석하여 값을 1로 설정하고 질의 실행 계획 출력을 지정한 것과 같다.
258 : 질의 최적화를 수행하여 생성된 질의 실행 계획을 출력하나 질의를 수행하지는 않는다. 256+2의 값으로 해석하여 2로 설정하고 질의 실행 계획 출력을 지정한 것과 같다. 질의 실행 계획을 살펴보고자 하나 실행 결과에는 관심이 없을 경우 유용한 설정이다.
513 : 질의 최적화를 수행하고 상세 질의 실행 계획을 출력한다. 512+1의 의미이다.
514 : 질의 최적화를 수행하고 상세 질의 실행 계획을 출력하나 질의는 실행하지는 않는다. 512+2의 의미이다.
참고
2, 258, 514와 같이 질의를 실행하지 않게 최적화 수준을 설정하는 경우 SELECT 문 뿐만 아니라 INSERT, UPDATE, DELETE, REPLACE, TRIGGER, SERIAL 문 등 모든 질의문이 실행되지 않는다.
CUBRID 질의 최적화기는 사용자에 의해 설정된 최적화 수준 값을 참조하여 최적화 여부와 질의 실행 계획의 출력 여부를 결정한다.
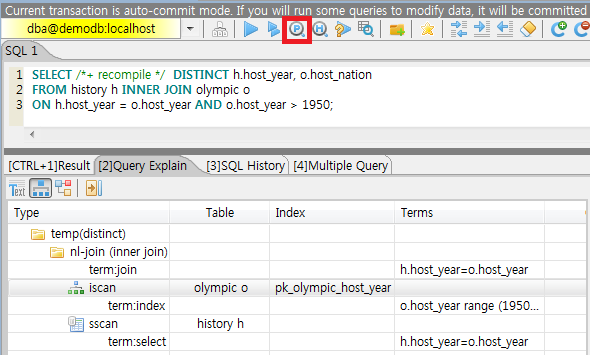
다음은 CSQL에서 “;plan simple” 명령 입력 또는 “SET OPTIMIZATION LEVEL 257;”을 입력 후 질의를 수행한 결과이다.
SET OPTIMIZATION LEVEL 257;
-- csql> ;plan simple
SELECT /*+ RECOMPILE */ DISTINCT h.host_year, o.host_nation
FROM history h INNER JOIN olympic o
ON h.host_year = o.host_year AND o.host_year > 1950;
Query plan:
Sort(distinct)
Nested-loop join(h.host_year=o.host_year)
Index scan(olympic o, pk_olympic_host_year, (o.host_year> ?:0 ))
Sequential scan(history h)
Sort(distinct): DISTINCT를 수행한다.
Nested-loop join: 조인 방식이 Nested-loop이다.
Index scan: olympic 테이블에 대해 pk_olympic_host_year를 사용하여 index scan. 이때 인덱스를 사용한 조건은 “o.host_year> ?”이다.
CSQL에서 “;plan detail” 명령 입력 또는 “SET OPTIMIZATION LEVEL 513;”을 입력 후 질의를 수행하면 상세 내용을 출력한다.
SET OPTIMIZATION LEVEL 513;
-- csql> ;plan detail
SELECT /*+ RECOMPILE */ DISTINCT h.host_year, o.host_nation
FROM history h INNER JOIN olympic o
ON h.host_year = o.host_year AND o.host_year > 1950;
Join graph segments (f indicates final):
seg[0]: [0]
seg[1]: host_year[0] (f)
seg[2]: [1]
seg[3]: host_nation[1] (f)
seg[4]: host_year[1]
Join graph nodes:
node[0]: history h(147/1)
node[1]: olympic o(25/1) (sargs 1)
Join graph equivalence classes:
eqclass[0]: host_year[0] host_year[1]
Join graph edges:
term[0]: h.host_year=o.host_year (sel 0.04) (join term) (mergeable) (inner-join) (indexable host_year[1]) (loc 0)
Join graph terms:
term[1]: o.host_year range (1950 gt_inf max) (sel 0.1) (rank 2) (sarg term) (not-join eligible) (indexable host_year[1]) (loc 0)
Query plan:
temp(distinct)
subplan: nl-join (inner join)
edge: term[0]
outer: iscan
class: o node[1]
index: pk_olympic_host_year term[1]
cost: 1 card 2
inner: sscan
class: h node[0]
sargs: term[0]
cost: 1 card 147
cost: 3 card 15
cost: 9 card 15
Query stmt:
select distinct h.host_year, o.host_nation from history h, olympic o where h.host_year=o.host_year and (o.host_year> ?:0 )
위의 출력 결과에서 질의 계획과 관련하여 봐야 할 정보는 “Query plan:”이며, 가장 안쪽의 윗줄부터 순서대로 실행된다. 즉, outer: iscan -> inner:scan이 nl-join에서 반복 수행되고, 마지막으로 temp(distinct)가 수행된다. “Join graph segments”는 “Query plan:”에서 필요한 정보를 좀더 확인하는 용도로 사용한다. 예를 들어 “Query plan:”에서 “term[0]”는 “Join graph segments”에서 “term[0]: h.host_year=o.host_year (sel 0.04) (join term) (mergeable) (inner-join) (indexable host_year[1]) (loc 0)”로 표현됨을 확인할 수 있다.
위의 “Query plan:” 각 항목에 대한 설명은 다음과 같다.
temp(distinct): (distinct)는 DISTINCT를 실행함을 의미한다. temp는 실행 결과를 임시 공간에 저장했음을 의미한다.
nl-join: “nl-join”은 조인 방식이 중첩 루프 조인(Nested loop join)임을 의미한다.
(inner join): 조인 종류가 “inner join”임을 의미한다.
outer: iscan: outer 테이블에서는 iscan(index scan)을 수행한다.
class: o node[1]: o라는 테이블을 사용하며 상세 정보는 Join graph segments의 node[1]을 확인한다.
index: pk_olympic_host_year term[1]: pk_olympic_host_year 인덱스를 사용하며 상세 정보는 Join graph segments의 term[1]을 확인한다.
cost: 해당 구문을 수행하는데 드는 비용이다.
card: 카디널리티(cardinality)를 의미한다. 이 값은 근사치임에 유의한다.
inner: sscan: inner 테이블에 sscan(sequential scan)을 수행한다.
class: h node[0]: h라는 테이블을 사용하며 상세 정보는 Join graph segments의 node[0]을 확인한다.
sargs: term[0]: sargs는 데이터 필터(인덱스를 사용하지 않는 WHERE 조건)를 나타내며, term[0]는 데이터 필터로 사용된 조건을 의미한다.
cost: 해당 구문을 수행하는데 드는 비용이다.
card: 카디널리티(cardinality)를 의미한다. 이 값은 근사치임에 유의한다.
cost: 전체 구문을 수행하는데 드는 비용이다. 앞서 수행된 모든 비용을 포함한다.
card: 카디널리티(cardinality)를 의미한다. 이 값은 근사치임에 유의한다.
질의 계획 관련 용어
다음은 질의 계획으로 출력되는 각 용어에 대한 의미를 정리한 것이다.
조인 방식: 질의 계획에서 출력되는 조인 방식은 위에서 “nl-join” 부분으로 다음과 같다.
nl-join: 중첩 루프 조인, Nested loop join
m-join: 정렬 병합 조인, Sort merge join
idx_join: 중첩 루프 조인인데 outer 테이블의 행(row)을 읽으면서 inner 테이블에서 인덱스를 사용하는 조인
조인 종류: 위에서 (inner join) 부분으로, 질의 계획에서 출력되는 조인 종류는 다음과 같다.
inner join
left outer join
right outer join: 질의 계획에서는 질의문의 “outer” 방향과 다른 방향이 출력될 수도 있다. 예를 들어, 질의문에서는 “right outer”로 지정했는데 질의 계획에는 “left outer”로 출력될 수도 있다.
cross join
조인 테이블의 종류: 위에서 outer/inner 부분으로, 중첩 루프 조인에서 루프의 어느 쪽에 위치하는가를 기준으로 outer 테이블과 inner 테이블로 나뉜다.
outer 테이블: 조인할 때 가장 처음에 읽을 기준 테이블
inner 테이블: 조인할 때 나중에 읽을 대상 테이블
스캔 방식: 위에서 iscan/sscan 부분으로, 해당 질의가 인덱스를 사용하는지 여부를 판단할 수 있다.
sscan: 순차 스캔(sequential scan). 풀 테이블 스캔(full table scan)이라고도 하며 인덱스를 사용하지 않고 테이블 전체를 스캔한다.
iscan: 인덱스 스캔(index scan). 인덱스를 사용하여 스캔할 데이터의 범위를 한정한다.
cost: CPU, IO 등 주로 리소스의 사용과 관련하여 비용을 내부적으로 산정한다.
card: 카디널리티(cardinality)를 의미하며, 선택될 것으로 예측되는 행의 개수이다.
다음은 USE_MERGE 힌트를 명시하여 m-join(정렬 병합 조인, sort merge join)이 적용되는 경우의 예이다. 일반적으로 정렬 병합 조인은 outer 테이블과 inner 테이블을 정렬하여 병합하는 것이 인덱스를 사용하여 중첩 루프 조인(nested loop join)을 수행하는 것보다 유리하다고 판단될 때만 사용해야 하며, 조인되는 두 테이블 모두 행의 개수가 매우 많은 경우 유리할 수 있다. 대부분의 경우 정렬 병합 조인을 수행하지 않는 것이 바람직하다.
참고
9.3 버전부터 질의문에 USE_MERGE 힌트를 명시하거나 cubrid.conf의 optimizer_enable_merge_join 값을 yes로 설정해야 정렬 병합 조인의 적용이 고려된다.
SET OPTIMIZATION LEVEL 513;
-- csql> ;plan detail
SELECT /*+ RECOMPILE USE_MERGE*/ DISTINCT h.host_year, o.host_nation
FROM history h LEFT OUTER JOIN olympic o ON h.host_year = o.host_year AND o.host_year > 1950;
Query plan:
temp(distinct)
subplan: temp
order: host_year[0]
subplan: m-join (left outer join)
edge: term[0]
outer: temp
order: host_year[0]
subplan: sscan
class: h node[0]
cost: 1 card 147
cost: 10 card 147
inner: temp
order: host_year[1]
subplan: iscan
class: o node[1]
index: pk_olympic_host_year term[1]
cost: 1 card 2
cost: 7 card 2
cost: 18 card 147
cost: 24 card 147
cost: 30 card 147
다음은 idx-join(인덱스 조인, index join)을 수행하는 경우의 예이다. inner 테이블의 조인 조건 칼럼에 인덱스가 있는 경우 inner 테이블의 인덱스를 사용하여 조인을 수행하는 것이 유리하다고 판단되면 USE_IDX 힌트를 명시하여 idx-join의 실행을 보장할 수 있다.
SET OPTIMIZATION LEVEL 513;
-- csql> ;plan detail
CREATE INDEX i_history_host_year ON history(host_year);
SELECT /*+ RECOMPILE */ DISTINCT h.host_year, o.host_nation
FROM history h INNER JOIN olympic o ON h.host_year = o.host_year;
Query plan:
temp(distinct)
subplan: idx-join (inner join)
outer: sscan
class: o node[1]
cost: 1 card 25
inner: iscan
class: h node[0]
index: i_history_host_year term[0] (covers)
cost: 1 card 147
cost: 2 card 147
cost: 9 card 147
위의 질의 계획에서 “inner: iscan”의 “index: i_history_host_year term[0]”에 “(covers)”가 출력되는데, 이는 커버링 인덱스 기능이 적용된다는 의미이다. 즉, inner 테이블에서 인덱스 내에 필요한 데이터가 있어서 데이터 저장소를 추가로 검색할 필요가 없게 된다.
조인 테이블 중 왼쪽 테이블이 오른쪽 테이블보다 행의 개수가 훨씬 작음을 확신할 때 ORDERED 힌트를 명시하여 왼쪽 테이블을 outer 테이블로, 오른쪽 테이블을 inner 테이블로 지정할 수 있다.
SELECT /*+ RECOMPILE ORDERED */ DISTINCT h.host_year, o.host_nation
FROM history h INNER JOIN olympic o ON h.host_year = o.host_year;
질의 프로파일링
SQL에 대한 성능 분석을 위해서는 질의 프로파일링(profiling) 기능을 사용할 수 있다. 질의 프로파일링을 위해서는 SET TRACE ON 구문으로 SQL 트레이스를 설정해야 하며, 프로파일링 결과를 출력하려면 SHOW TRACE 구문을 수행해야 한다.
또한 SHOW TRACE 결과 출력 시 질의 실행 계획을 항상 포함하려면 /*+ RECOMPLIE */ 힌트를 추가해야 한다.
SET TRACE ON 구문의 형식은 다음과 같다.
SET TRACE {ON | OFF} [OUTPUT {TEXT | JSON}]
ON: SQL 트레이스를 on한다.
OFF: SQL 트레이스를 off한다.
OUTPUT TEXT: 일반 TEXT 형식으로 출력한다. OUTPUT 이하 절을 생략하면 TEXT 형식으로 출력한다.
OUTPUT JSON: JSON 형식으로 출력한다.
아래와 같이 SHOW TRACE 구문을 실행하면 SQL을 트레이스한 결과를 문자열로 출력한다.
SHOW TRACE;
다음은 SQL 트레이스를 ON으로 설정하고 질의를 수행한 후, 해당 질의에 대해 트레이스 결과를 출력하는 예이다.
csql> SET TRACE ON;
csql> SELECT /*+ RECOMPILE */ o.host_year, o.host_nation, o.host_city, SUM(p.gold)
FROM OLYMPIC o, PARTICIPANT p
WHERE o.host_year = p.host_year AND p.gold > 20
GROUP BY o.host_nation;
csql> SHOW TRACE;
=== <Result of SELECT Command in Line 2> ===
trace
======================
'
Query Plan:
SORT (group by)
NESTED LOOPS (inner join)
TABLE SCAN (o)
INDEX SCAN (p.fk_participant_host_year) (key range: o.host_year=p.host_year)
rewritten query: select o.host_year, o.host_nation, o.host_city, sum(p.gold) from OLYMPIC o, PARTICIPANT p where o.host_year=p.host_year and (p.gold> ?:0 ) group by o.host_nation
Trace Statistics:
SELECT (time: 1, fetch: 975, ioread: 2)
SCAN (table: olympic), (heap time: 0, fetch: 26, ioread: 0, readrows: 25, rows: 25)
SCAN (index: participant.fk_participant_host_year), (btree time: 1, fetch: 941, ioread: 2, readkeys: 5, filteredkeys: 5, rows: 916) (lookup time: 0, rows: 14)
GROUPBY (time: 0, sort: true, page: 0, ioread: 0, rows: 5)
'
위에서 “Trace Statistics:” 이하가 트레이스 결과를 출력한 것이며 트레이스 결과의 각 항목을 설명하면 다음과 같다.
SELECT (time: 1, fetch: 975, ioread: 2)
time: 4 => 전체 질의 시간 4ms 소요.
fetch: 975 => 페이지에 대해 975회 fetch(개수가 아닌 접근 회수임. 같은 페이지를 다시 fetch하더라도 회수가 증가함).
ioread: 2회 디스크 접근.
: SELECT 질의에 대한 전체 통계이다. fetch 회수와 ioread 회수는 질의를 재실행하면 질의 결과의 일부를 버퍼에서 가져오게 되면서 줄어들 수 있다.
SCAN (table: olympic), (heap time: 0, fetch: 26, ioread: 0, readrows: 25, rows: 25)
heap time: 0 => 소요 시간은 1ms 미만. millisecond보다 작은 값은 버림하기 때문에 1ms 미만의 소요 시간은 0으로 표시된다.
fetch: 26 => 페이지를 fetch한 회수는 26건.
ioread: 0 => 디스크에 접근한 회수는 0.
readrows: 25 => 스캔 시 읽은 행의 개수는 25.
rows: 25 => 결과 행의 개수는 25.
: olympic 테이블에 대한 힙 스캔 통계이다.
SCAN (index: participant.fk_participant_host_year), (btree time: 1, fetch: 941, ioread: 2, readkeys: 5, filteredkeys: 5, rows: 916) (lookup time: 0, rows: 14)
btree time: 1 => 소요 시간은 1ms.
fetch: 941 => 페이지를 fetch한 회수는 941.
ioread: 2 => 디스크에 접근한 회수는 2회.
readkeys: 5 => 읽은 키의 개수는 5.
filteredkeys: 5 => 키 필터가 적용된 키의 개수는 5.
rows: 916 => 스캔한 행 개수는 916.
lookup time: 0 => 인덱스 스캔 후 데이터에 접근하는데 소요된 시간은 1ms 미만.
rows: 14 => 데이터 필터까지 적용한 이후의 행 개수로, 이 질의문에서는 데이터 필터인 “p.gold > 20”을 적용했을 때 행의 개수는 14.
: participant.fk_participant_host_year 인덱스에 대한 인덱스 스캔 통계이다.
GROUPBY (time: 0, sort: true, page: 0, ioread: 0, rows: 5)
time: 0 => group by 적용 시 소요된 시간은 1ms 미만.
sort: true => 정렬이 적용되므로 true.
page: 0 => 정렬에 사용된 임시 페이지 개수가 0.
ioread: 0 => 디스크 접근에 소요된 시간은 1ms 미만.
rows: 5 => group by에 대한 결과 행의 개수는 5개.
: group by에 대한 통계이다.
다음은 3개의 테이블을 조인한 예이다.
csql> SET TRACE ON;
csql> SELECT /*+ RECOMPILE */ o.host_year, o.host_nation, o.host_city, n.name, SUM(p.gold), SUM(p.silver), SUM(p.bronze)
FROM OLYMPIC o, PARTICIPANT p, NATION n
WHERE o.host_year = p.host_year AND p.nation_code = n.code AND p.gold > 10
GROUP BY o.host_nation;
csql> SHOW TRACE;
trace
======================
'
Query Plan:
SORT (group by)
NESTED LOOPS (inner join)
NESTED LOOPS (inner join)
TABLE SCAN (o)
INDEX SCAN (p.fk_participant_host_year) (key range: (o.host_year=p.host_year))
INDEX SCAN (n.pk_nation_code) (key range: p.nation_code=n.code)
rewritten query: select o.host_year, o.host_nation, o.host_city, n.[name], sum(p.gold), sum(p.silver), sum(p.bronze) from OLYMPIC o, PARTICIPANT p, NATION n where (o.host_year=p.host_year and p.nation_code=n.code and (p.gold> ?:0 )) group by o.host_nation
Trace Statistics:
SELECT (time: 1, fetch: 1059, ioread: 2)
SCAN (table: olympic), (heap time: 0, fetch: 26, ioread: 0, readrows: 25, rows: 25)
SCAN (index: participant.fk_participant_host_year), (btree time: 1, fetch: 945, ioread: 2, readkeys: 5, filteredkeys: 5, rows: 916) (lookup time: 0, rows: 38)
SCAN (index: nation.pk_nation_code), (btree time: 0, fetch: 76, ioread: 0, readkeys: 38, filteredkeys: 38, rows: 38) (lookup time: 0, rows: 38)
GROUPBY (time: 0, sort: true, page: 0, ioread: 0, rows: 5)
'
다음은 트레이스 항목에 대한 설명이다.
SELECT
time: 해당 질의에 대한 전체 수행 시간(ms)
fetch: 해당 질의에 대해 페이지를 fetch한 회수
ioread: 해당 질의에 대한 전체 I/O 읽기 회수. 데이터를 읽을 때 물리적으로 디스크에 접근한 회수
SCAN
heap: 인덱스 없이 데이터를 스캔하는 작업
time, fetch, ioread: heap에서 해당 연산 수행 시 소요된 시간(ms), fetch 회수, I/O 읽기 회수
readrows: 해당 연산 수행 시 읽은 행의 개수
rows: 해당 연산에 대한 결과 행의 개수
btree: 인덱스 스캔하는 작업
time, fetch, ioread: btree에서 해당 연산 수행 시 소요된 시간(ms), fetch 회수, I/O 읽기 회수
readkeys: btree에서 해당 연산 수행 시 읽은 키의 개수
filteredkeys: 읽은 키 중에 키 필터가 적용된 키의 개수
rows: 해당 연산에 대한 결과 행의 개수로, 키 필터가 적용된 결과 행의 개수
lookup: 인덱스 스캔 후 데이터에 접근하는 작업
time: 해당 연산 수행 시 소요된 시간(ms)
rows: 해당 연산에 대한 결과 행의 개수로, 데이터 필터가 적용된 결과 행의 개수
GROUPBY
time: 해당 연산 수행 시 소요된 시간(ms)
sort: 정렬 여부
page: 정렬에 사용된 임시 페이지 개수로, 내부 정렬 버퍼 외에 사용한 페이지 개수.
rows: 해당 연산에 대한 결과 행의 개수
INDEX SCAN
key range: 키의 범위
covered: 커버링 인덱스 적용 여부(true/false)
loose: loose index scan 적용 여부(true/false)
hash: 집계 함수에서 투플 정렬 시 해시 집계 방식 적용 여부(true/false). NO_HASH_AGGREGATE 힌트를 참고한다.
위의 예는 JSON 형식으로도 출력할 수 있다.
csql> SET TRACE ON OUTPUT JSON;
csql> SELECT n.name, a.name FROM athlete a, nation n WHERE n.code=a.nation_code;
csql> SHOW TRACE;
trace
======================
'{
"Trace Statistics": {
"SELECT": {
"time": 29,
"fetch": 5836,
"ioread": 3,
"SCAN": {
"access": "temp",
"temp": {
"time": 5,
"fetch": 34,
"ioread": 0,
"readrows": 6677,
"rows": 6677
}
},
"MERGELIST": {
"outer": {
"SELECT": {
"time": 0,
"fetch": 2,
"ioread": 0,
"SCAN": {
"access": "table (nation)",
"heap": {
"time": 0,
"fetch": 1,
"ioread": 0,
"readrows": 215,
"rows": 215
}
},
"ORDERBY": {
"time": 0,
"sort": true,
"page": 21,
"ioread": 3
}
}
}
}
}
}
}'
CSQL 인터프리터에서 트레이스를 자동으로 설정하는 명령을 사용하면 SHOW TRACE; 구문을 별도로 실행하지 않아도 질의 실행 결과를 출력한 후 자동으로 트레이스 결과를 출력한다.
CSQL 인터프리터에서 트레이스를 자동으로 설정하는 방법은 SQL 트레이스 설정을 참고한다.
참고
독립 모드(-S 옵션 사용)로 실행한 CSQL 인터프리터는 SQL 트레이스 기능을 지원하지 않는다.
여러 개의 SQL을 한 번에 처리하는 경우(batch query, array query) 질의는 프로파일링되지 않는다.
SQL 힌트
사용자는 질의문에 힌트를 주어 해당 질의 성능을 높일 수 있다. 질의 최적화기는 질의문에 대한 최적화 작업을 수행할 때 SQL 힌트를 참고하여 효율적인 실행 계획을 생성한다. CUBRID에서 지원하는 SQL 힌트는 테이블 조인 관련 힌트, 인덱스 관련 힌트가 있다.
{ SELECT | UPDATE | DELETE } /*+ <hint> [ { <hint> } ... ] */ ...;
MERGE /*+ <merge_statement_hint> [ { <merge_statement_hint> } ... ] */ INTO ...;
<hint> ::=
USE_NL [ (<spec_name_comma_list>) ] |
USE_IDX [ (<spec_name_comma_list>) ] |
USE_MERGE [ (<spec_name_comma_list>) ] |
ORDERED |
USE_DESC_IDX |
INDEX_SS [ (<spec_name_comma_list>) ] |
INDEX_LS |
NO_DESC_IDX |
NO_COVERING_IDX |
NO_MULTI_RANGE_OPT |
NO_SORT_LIMIT |
NO_HASH_AGGREGATE |
RECOMPILE
<spec_name_comma_list> ::= <spec_name> [, <spec_name>, ... ]
<spec_name> ::= table_name | view_name
<merge_statement_hint> ::=
USE_UPDATE_INDEX (<update_index_list>) |
USE_DELETE_INDEX (<insert_index_list>) |
RECOMPILE
SQL 힌트는 주석에 더하기 기호(+)를 함께 사용하여 지정한다. 힌트를 사용하는 방법은 주석 절에 소개된 바와 같이 세 가지 방식이 있다. 따라서 SQL 힌트도 다음과 같이 세 가지 방식으로 사용할 수 있다.
/*+ hint */
–+ hint
//+ hint
힌트 주석은 반드시 키워드 SELECT, UPDATE or DELETE 등의 예약어 다음에 나타나야 하고, 더하기 기호(+)가 주석에서 첫 번째 문자로 시작되어야 한다. 여러 개의 힌트를 지정할 때는 공백이 구분자로 사용된다. 여러 개의 힌트를 지정할 때는 공백이 구분자로 사용된다.
SELECT, UPDATE, DELETE 문에는 다음 힌트가 지정될 수 있다.
USE_NL: 테이블 조인과 관련한 힌트로서, 질의 최적화기 중첩 루프 조인 실행 계획을 만든다.
USE_MERGE: 테이블 조인과 관련한 힌트로서, 질의 최적화기는 정렬 병합 조인 실행 계획을 만든다.
ORDERED: 테이블 조인과 관련한 힌트로서, 질의 최적화기는 FROM 절에 명시된 테이블의 순서대로 조인하는 실행 계획을 만든다. FROM 절에서 왼쪽 테이블은 조인의 외부 테이블이 되고, 오른쪽 테이블은 내부 테이블이 된다.
USE_IDX: 인덱스 관련한 힌트로서, 질의 최적화기는 명시된 테이블에 대해 인덱스 조인 실행 계획을 만든다.
USE_DESC_IDX: 내림차순 스캔을 위한 힌트이다. 자세한 내용은 내림차순 인덱스 스캔을 참고한다.
INDEX_SS: index skip scan 실행 계획을 고려한다. 자세한 내용은 Index Skip Scan을 참고한다.
INDEX_LS: loose index scan 실행 계획을 고려한다. 자세한 내용은 Loose Index Scan을 참고한다.
NO_DESC_IDX: 내림차순 스캔을 사용하지 않도록 하는 힌트이다.
NO_COVERING_IDX: 커버링 인덱스 기능을 사용하지 않도록 하는 힌트이다. 자세한 내용은 커버링 인덱스 를 참고한다.
NO_MULTI_RANGE_OPT: 다중 키 범위 최적화 기능을 사용하지 않도록 하는 힌트이다. 자세한 내용은 다중 키 범위 최적화 를 참고한다.
NO_SORT_LIMIT: SORT-LIMIT 최적화를 사용하지 않기 위한 힌트이다. 자세한 내용은 SORT-LIMIT 최적화를 참고한다.
NO_HASH_AGGREGATE: 집계 함수에서 투플을 정렬할 때 해싱을 사용하지 않도록 하는 힌트이다. 그 대신, 외부 정렬(external sorting)이 집계 함수에서 사용된다. 인-메모리(in-memory) 해시 테이블을 사용하여, CUBRID는 정렬할 때 필요로 하는 데이터의 양을 줄이거나 심지어는 제거할 수 있다. 그러나, 어떤 경우에는 해시 집계 방식이 실패할 것이라는 것을 미리 알고 전체적으로 해시 집계 과정을 생략하기 위해 이 힌트를 사용할 수 있다. 해시 집계 방식의 메모리 크기를 설정하기 위해서는 max_agg_hash_size를 참고한다.
참고
DISTINCT한 값을 계산하는 함수들(예. AVG(DISTINCT x))과 GROUP_CONCAT, MEDIAN 함수들은 각 그룹의 투플들에 대해 외부 정렬(external sorting) 과정을 요구하므로 해시 집계 방식이 동작하지 않을 것이다.
RECOMPILE : 질의 실행 계획을 리컴파일한다. 캐시에 저장된 기존 질의 실행 계획을 삭제하고 새로운 질의 실행 계획을 수립하기 위해 이 힌트를 사용한다.
참고
<spec_name>이 USE_NL, USE_IDX, USE_MERGE와 함께 지정될 경우 해당 조인 방법은 <spec_name>에 대해서만 적용된다.
SELECT /*+ ORDERED USE_NL(b) USE_NL(c) USE_MERGE(d) */ *
FROM a INNER JOIN b ON a.col=b.col
INNER JOIN c ON b.col=c.col INNER JOIN d ON c.col=d.col;
위와 같은 질의를 수행한다면 테이블 a와 b가 조인될 때는 USE_NL이 적용되고 테이블 c가 조인될 때도 USE_NL이 적용되며, 테이블 d가 조인될 때는 USE_MERGE가 적용된다.
<spec_name>이 주어지지 않고 USE_NL과 USE_MERGE가 함께 지정된 경우 주어진 힌트는 무시된다. 일부 경우에 질의 최적화기는 주어진 힌트에 따라 질의 실행 계획을 만들지 못할 수 있다. 예를 들어 오른쪽 외부 조인에 대해 USE_NL을 지정한 경우 이 질의는 내부적으로 왼쪽 외부 조인 질의로 변환이 되어 조인 순서는 보장되지 않을 수 있다.
MERGE 문에는 다음과 같은 힌트를 사용할 수 있다.
USE_INSERT_INDEX (<insert_index_list>): MERGE 문의 INSERT 절에서 사용되는 인덱스 힌트. insert_index_list에 INSERT 절을 수행할 때 사용할 인덱스 이름을 나열한다. MERGE 문의 <join_condition>에 해당 힌트가 적용된다.
USE_UPDATE_INDEX (<update_index_list>): MERGE 문의 UPDATE 절에서 사용되는 인덱스 힌트. update_index_list에 UPDATE 절을 수행할 때 사용할 인덱스 이름을 나열한다. MERGE 문의 <join_condition>과 <update_condition>에 해당 힌트가 적용된다.
RECOMPILE: 위의 RECOMPILE을 참고한다.
조인 시 사용하는 힌트의 경우 힌트 안에 조인할 테이블이나 뷰 이름을 명시할 수 있는데, 이때 테이블 이름/뷰 이름은 “,”로 구분한다.
SELECT /*+ USE_NL(a, b) */ *
FROM a INNER JOIN b ON a.col=b.col;
다음은 ‘심권호’ 선수가 메달을 획득한 연도와 메달 종류를 구하는 예제이다. 다음과 같은 질의로 표현이 되는데, 질의최적화기는 athlete 테이블을 외부 테이블로 하고, game 테이블을 내부 테이블로 하는 중첩 루프 조인 실행 계획을 만든다.
-- csql> ;plan_detail
SELECT /*+ USE_NL ORDERED */ a.name, b.host_year, b.medal
FROM athlete a, game b
WHERE a.name = 'Sim Kwon Ho' AND a.code = b.athlete_code;
Query plan:
idx-join (inner join)
outer: sscan
class: a node[0]
sargs: term[1]
cost: 44 card 7
inner: iscan
class: b node[1]
index: fk_game_athlete_code term[0]
cost: 3 card 8653
cost: 73 card 9
다음은 USE_NL 힌트 사용 시 사용하는 테이블을 명시하는 예이다.
-- csql> ;plan_detail
SELECT /*+ USE_NL(a,b) */ a.name, b.host_year, b.medal
FROM athlete a, game b
WHERE a.name = 'Sim Kwon Ho' AND a.code = b.athlete_code;
인덱스 힌트
인덱스 힌트 구문은 질의에서 인덱스를 지정할 수 있도록 해서 질의 처리기가 적절한 인덱스를 선택할 수 있게 한다. 이와 같은 인덱스 힌트 구문은 USING INDEX 절을 사용하는 방식과 FROM 절에 { USE | FORCE | IGNORE } INDEX 구문을 사용하는 방식이 있다.
USING INDEX
USING INDEX 절은 SELECT, DELETE, UPDATE 문의 WHERE 절 다음에 지정되어야 한다. USING INDEX 절에 강제로 순차 스캔 또는 인덱스 스캔이 사용되게 하거나, 성능에 유리한 인덱스가 포함되도록 한다.
USING INDEX 절에 인덱스 이름의 리스트가 지정되면 질의 최적화기는 지정된 인덱스만을 대상으로 질의 실행 비용을 계산하고, 지정된 인덱스의 인덱스 스캔 비용과 순차 스캔 비용을 비교하여 최적의 실행 계획을 만든다(CUBRID는 실행 계획을 선택할 때 비용 기반의 질의 최적화를 수행한다).
USING INDEX 절은 ORDER BY 없이 원하는 순서로 결과를 얻고자 할 때 유용하게 사용될 수 있다. CUBRID는 인덱스 스캔을 하면 인덱스에 저장된 순서로 결과가 생성되는데, 한 테이블에 여러 인덱스가 있을 경우 특정 인덱스의 순서로 질의 결과를 얻고자 할 때 USING INDEX 를 사용할 수 있다.
SELECT ... WHERE ...
[USING INDEX { NONE | [ ALL EXCEPT ] <index_spec> [ {, <index_spec> } ...] } ] [ ; ]
DELETE ... WHERE ...
[USING INDEX { NONE | [ ALL EXCEPT ] <index_spec> [ {, <index_spec> } ...] } ] [ ; ]
UPDATE ... WHERE ...
[USING INDEX { NONE | [ ALL EXCEPT ] <index_spec> [ {, <index_spec> } ...] } ] [ ; ]
<index_spec> ::=
[table_spec.]index_name [(+) | (-)] |
table_spec.NONE
NONE: NONE 을 지정한 경우 모든 테이블에 대해서 순차 스캔이 사용된다.
ALL EXCEPT: 질의 수행 시 지정한 인덱스를 제외한 모든 인덱스가 사용될 수 있다.
index_name(+): 인덱스 이름 뒤에 (+)를 지정하면 해당 인덱스 선택이 우선시 된다. 해당 인덱스가 해당 질의를 수행하는데 적합하지 않으면 선택하지 않는다.
index_name(-): 인덱스 이름 뒤에 (-)를 지정하면 해당 인덱스가 선택에서 제외된다.
table_spec.NONE: 해당 테이블의 모든 인덱스가 선택에서 제외되어 순차 스캔이 사용된다.
USE, FORCE, IGNORE INDEX
FROM 절의 테이블 명세 뒤에 USE, FORCE, IGNORE INDEX 구문을 통해서 인덱스 힌트를 지정할 수 있다.
FROM table_spec [ <index_hint_clause> ] ...
<index_hint_clause> ::=
{ USE | FORCE | IGNORE } INDEX ( <index_spec> [, <index_spec> ...] )
<index_spec> ::=
[table_spec.]index_name
USE INDEX ( <index_spec> ): 지정한 인덱스들만 선택 시에 고려한다.
FORCE INDEX ( <index_spec> ): 해당 인덱스 선택이 우선시 된다.
IGNORE INDEX ( <index_spec> ): 지정한 인덱스들은 선택에서 제외된다.
USE, FORCE, IGNORE INDEX 구문은 시스템에 의해 자동적으로 적절한 USING INDEX 구문으로 재작성된다.
인덱스 힌트 사용 예
CREATE TABLE athlete2 (
code SMALLINT PRIMARY KEY,
name VARCHAR(40) NOT NULL,
gender CHAR(1),
nation_code CHAR(3),
event VARCHAR(30)
);
CREATE UNIQUE INDEX athlete2_idx1 ON athlete2 (code, nation_code);
CREATE INDEX athlete2_idx2 ON athlete2 (gender, nation_code);
아래 2개의 질의는 같은 동작을 수행하며, 지정된 athlete2_idx2 인덱스 스캔 비용이 순차 스캔 비용보다 작을 경우 해당 인덱스 스캔을 선택하게 된다.
SELECT /*+ RECOMPILE */ *
FROM athlete2 USE INDEX (athlete2_idx2)
WHERE gender='M' AND nation_code='USA';
SELECT /*+ RECOMPILE */ *
FROM athlete2
WHERE gender='M' AND nation_code='USA'
USING INDEX athlete2_idx2;
아래 2개의 질의는 같은 동작을 수행하며, 항상 athlete2_idx2를 사용한다.
SELECT /*+ RECOMPILE */ *
FROM athlete2 FORCE INDEX (athlete2_idx2)
WHERE gender='M' AND nation_code='USA';
SELECT /*+ RECOMPILE */ *
FROM athlete2
WHERE gender='M' AND nation_code='USA'
USING INDEX athlete2_idx2(+);
아래 2개의 질의는 같은 동작을 수행하며, 질의 수행 시 athlete2_idx2를 사용하지 않는다.
SELECT /*+ RECOMPILE */ *
FROM athlete2 IGNORE INDEX (athlete2_idx2)
WHERE gender='M' AND nation_code='USA';
SELECT /*+ RECOMPILE */ *
FROM athlete2
WHERE gender='M' AND nation_code='USA'
USING INDEX athlete2_idx2(-);
다음 질의는 수행 시 항상 순차 스캔을 선택한다.
SELECT *
FROM athlete2
WHERE gender='M' AND nation_code='USA'
USING INDEX NONE;
SELECT *
FROM athlete2
WHERE gender='M' AND nation_code='USA'
USING INDEX athlete2.NONE;
다음 질의는 수행 시 athlete2_idx2를 제외한 모든 인덱스의 사용이 가능하도록 한다.
SELECT *
FROM athlete2
WHERE gender='M' AND nation_code='USA'
USING INDEX ALL EXCEPT athlete2_idx2;
다음과 같이 USE INDEX 구문 또는 USING INDEX 구문에서 여러 인덱스를 지정한 경우 질의 최적화기는 지정된 인덱스 중 하나를 선택한다.
SELECT *
FROM athlete2 USE INDEX (athlete2_idx2, athlete2_idx1)
WHERE gender='M' AND nation_code='USA';
SELECT *
FROM athlete2
WHERE gender='M' AND nation_code='USA'
USING INDEX athlete2_idx2, athlete2_idx1;
여러 개의 테이블에 대해 질의를 수행하는 경우, 한 테이블에서는 특정 인덱스를 사용하여 인덱스 스캔을 하고 다른 테이블에서는 순차 스캔을 하도록 지정할 수 있다. 이러한 질의는 다음과 같은 형태가 된다.
SELECT *
FROM tab1, tab2
WHERE ...
USING INDEX tab1.idx1, tab2.NONE;
인덱스 힌트 구문이 있는 질의를 수행할 때 질의 최적화기는 인덱스가 지정되지 않는 테이블에 대해서는 해당 테이블의 사용 가능한 모든 인덱스를 고려한다. 예를 들어, tab1 테이블에는 인덱스 idx1, idx2 이 있고 tab2 테이블에는 인덱스 idx3, idx4, idx5 가 있는 경우, tab1 에 대한 인덱스만 지정하고 tab2 에 대한 인덱스를 지정하지 않으면 질의 최적화기는 tab2 의 인덱스도 고려하여 동작한다.
SELECT ...
FROM tab1, tab2 USE INDEX(tab1.idx1)
WHERE ... ;
SELECT ...
FROM tab1, tab2
WHERE ...
USING INDEX tab1.idx1;
위의 예제의 경우에 테이블 tab1의 순차 스캔과 idx1 인덱스 스캔을 비교하여 테이블 tab1의 스캔 방법을 선택하며, 테이블 tab2의 순차 스캔과 idx3, idx4, idx5 인덱스 스캔을 비교하여 테이블 tab2의 스캔 방법을 선택하게 된다.
특별한 인덱스
필터링된 인덱스
필터링된 인덱스(filtered index)는 한 테이블에 대해 잘 정의된 부분 집합을 정렬하거나 찾거나 연산해야 할 때 사용되며, 전체 데이터에서 조건에 부합하는 일부 데이터만 인덱스에 유지하므로 부분 인덱스(partial index)라고도 한다.
CREATE /*+ hints */ INDEX index_name
ON table_name (col1, col2, ...)
WHERE <filter_predicate>;
ALTER /*+ hints */ INDEX index_name
[ ON table_name (col1, col2, ...)
[ WHERE <filter_predicate> ] ]
REBUILD;
<filter_predicate> ::= <filter_predicate> AND <expression> | <expression>
<filter_predicate>: 칼럼과 상수 간 비교 조건. 조건이 여러 개인 경우 AND 로 연결된 경우에만 필터가 될 수 있다. 필터 조건으로 CUBRID에서 지원하는 대부분의 연산자와 함수가 포함될 수 있다. 그러나 현재 날짜/시간을 출력하는 날짜/시간 함수(예:
SYS_DATETIME()), 랜덤 함수(예:RAND())와 같이 같은 입력에 대해 다른 결과를 출력하는 함수는 허용되지 않는다.
필터링된 인덱스를 적용하여 질의를 처리하려면 USE INDEX 구문 또는 FORCE INDEX 구문을 통해 해당 필터링된 인덱스를 반드시 명시해야 한다.
USING INDEX 절 또는 USE INDEX 구문을 통해 필터링된 인덱스를 명시하는 경우:
인덱스를 구성하는 칼럼이 WHERE 절의 조건에 포함되어 있지 않으면 필터링된 인덱스를 사용하지 않는다.
CREATE TABLE blogtopic ( blogID BIGINT NOT NULL, title VARCHAR(128), author VARCHAR(128), content VARCHAR(8096), postDate TIMESTAMP NOT NULL, deleted SMALLINT DEFAULT 0 ); CREATE INDEX my_filter_index ON blogtopic(postDate) WHERE deleted=0;아래 질의에서 my_filter_index를 구성하는 칼럼인 postDate 가 WHERE 조건에 포함되어 있으므로, USE INDEX 구문으로도 인덱스를 사용할 수 있다.
SELECT * FROM blogtopic USE INDEX (my_filter_index) WHERE postDate>'2010-01-01' AND deleted=0;USING INDEX <index_name>(+) 절 또는 FORCE INDEX 구문을 통해 필터링된 인덱스를 명시하는 경우:
인덱스를 구성하는 칼럼이 WHERE 절의 조건에 포함되어 있지 않더라도 필터링된 인덱스를 사용한다.
아래 질의에서는 my_filter_index 의 인덱스를 구성하는 칼럼이 WHERE 조건에 포함되어 있지 않으므로, USE INDEX 구문으로는 인덱스를 사용할 수 없다.
SELECT * FROM blogtopic USE INDEX (my_filter_index) WHERE author = 'David' AND deleted=0;따라서, my_filter_index 인덱스를 사용하려면 다음과 같이 FORCE INDEX 구문을 사용하여 인덱스 사용을 강제해야 한다.
SELECT * FROM blogtopic FORCE INDEX (my_filter_index) WHERE author = 'David' AND deleted=0;
다음은 버그/이슈를 유지하는 버그 트래킹 시스템의 예이다. 일정 기간의 개발 활동 이후 bugs 테이블에는 버그들이 기록되어 있는데, 이들 대부분은 오래 전에 종료된 상태이다. 버그 트래킹 시스템은 여전히 열린(open) 상태의 새로운 버그를 찾기 위해 해당 테이블에 질의를 한다. 이 경우 버그 테이블의 인덱스는 닫힌(closed) 버그의 레코드들에 대해 알 필요가 없다. 이런 경우 필터링된 인덱스는 열린 버그만 인덱싱하는 것을 허용한다.
CREATE TABLE bugs
(
bugID BIGINT NOT NULL,
CreationDate TIMESTAMP,
Author VARCHAR(255),
Subject VARCHAR(255),
Description VARCHAR(255),
CurrentStatus INTEGER,
Closed SMALLINT
);
열린 상태의 버그만을 위한 인덱스는 다음 문장으로 생성될 수 있다.
CREATE INDEX idx_open_bugs ON bugs(bugID) WHERE Closed = 0;
열린 상태의 버그에만 관심있는 질의 처리를 위해 해당 인덱스를 인덱스 힌트로 지정하면, 필터링된 인덱스를 통하여 더 적은 인덱스 페이지를 접근하여 질의 결과를 생성할 수 있게 된다.
SELECT *
FROM bugs
WHERE Author = 'madden' AND Subject LIKE '%fopen%' AND Closed = 0
USING INDEX idx_open_bugs(+);
SELECT *
FROM bugs FORCE INDEX (idx_open_bugs)
WHERE CreationDate > CURRENT_DATE - 10 AND Closed = 0;
위의 예에서 “USING INDEX idx_open_bugs” 또는 “USE INDEX (idx_open_bugs)” 를 사용하는 경우, idx_open_bugs 인덱스를 사용하지 않고 질의를 수행하게 된다.
경고
필터링된 인덱스 생성 조건과 질의 조건이 부합되지 않음에도 불구하고 인덱스 힌트 구문으로 인덱스를 명시하여 질의를 수행하면 명시된 인덱스를 선택하여 수행하므로, 주어진 검색 조건에 부합하지 않는 질의 결과를 출력할 수 있음에 주의한다.
참고
제약 사항
필터링된 인덱스는 일반 인덱스만 허용한다. 예를 들어, 필터링된 유일한(unique) 인덱스는 허용하지 않는다. 또한, 필터링된 인덱스를 구성하는 칼럼 값이 모두 NULL이 가능한 경우는 허용하지 않는다. 예를 들어, 아래의 경우는 Author 값이 NULL일 수 있으므로 허용하지 않는다.
CREATE INDEX idx_open_bugs ON bugs (Author) WHERE Closed = 0;
ERROR: before ' ; '
Invalid filter expression (bugs.Closed=0) for index.
하지만 아래의 경우는 Author 값이 NULL이더라도 CreationDate 값이 NULL일 수 없으므로 허용한다.
CREATE INDEX idx_open_bugs ON bugs (Author, CreationDate) WHERE Closed = 0;
다음은 인덱스 필터 조건으로 허용하지 않는 경우이다.
날짜/시간 함수 또는 랜덤 함수와 같이 입력이 같은데 결과가 매번 다른 함수
CREATE INDEX idx ON bugs(creationdate) WHERE creationdate > SYS_DATETIME;ERROR: before ' ; ' 'sys_datetime ' is not allowed in a filter expression for index.CREATE INDEX idx ON bugs(bugID) WHERE bugID > RAND();ERROR: before ' ; ' 'rand ' is not allowed in a filter expression for index.OR 연산자를 사용하는 경우
CREATE INDEX IDX ON bugs (bugID) WHERE bugID > 10 OR bugID = 3;ERROR: before ' ; ' ' or ' is not allowed in a filter expression for index.시리얼 관련 함수와 의사 칼럼을 포함한 경우
인덱스를 생성할 수 없는 타입을 사용하는 함수
SET 타입을 인자로 받는 연산자와 함수
LOB 파일을 생성하는 함수 (
CHAR_TO_BLOB(),CHAR_TO_CLOB(),BIT_TO_BLOB(),BLOB_FROM_FILE(),CLOB_FROM_FILE())
IS NULL 연산자는 인덱스를 구성하는 칼럼들 중 적어도 하나가 NULL 이 아닐 경우에만 사용 가능
CREATE TABLE t (a INT, b INT); -- IS NULL cannot be used with expressions CREATE INDEX idx ON t (a) WHERE (not a) IS NULL;ERROR: before ' ; ' Invalid filter expression (( not t.a<>0) is null ) for index.CREATE INDEX idx ON t (a) WHERE (a+1) IS NULL;ERROR: before ' ; ' Invalid filter expression ((t.a+1) is null ) for index.-- At least one attribute must not be used with IS NULL CREATE INDEX idx ON t(a,b) WHERE a IS NULL ;ERROR: before ' ; ' Invalid filter expression (t.a is null ) for index.CREATE INDEX idx ON t(a,b) WHERE a IS NULL and b IS NULL;ERROR: before ' ; ' Invalid filter expression (t.a is null and t.b is null ) for index.CREATE INDEX idx ON t(a,b) WHERE a IS NULL and b IS NOT NULL;필터링된 인덱스에 대한 index skip scan(ISS)은 지원되지 않는다.
필터링된 인덱스에서 사용되는 조건 문자열의 길이는 128자로 제한한다.
CREATE TABLE t(VeryLongColumnNameOfTypeInteger INT); CREATE INDEX idx ON t(VeryLongColumnNameOfTypeInteger) WHERE VeryLongColumnNameOfTypeInteger > 3 AND VeryLongColumnNameOfTypeInteger < 10 AND SQRT(VeryLongColumnNameOfTypeInteger) < 3 AND SQRT(VeryLongColumnNameOfTypeInteger) < 10;ERROR: before ' ; ' The maximum length of filter predicate string must be 128.
함수 기반 인덱스
함수 기반 인덱스(function-based index)는 특정 함수를 이용하여 테이블 행들로부터 값의 조합에 기반한 데이터를 정렬하거나 찾고 싶을 때 사용한다. 예를 들어, 공백을 무시한 문자열을 찾는 작업을 하고 싶을 때 이러한 기능을 수행하는 함수를 이용하게 되는데, 함수를 통해 칼럼 값을 변경하게 되면 일반 인덱스를 통해서 인덱스 스캔을 할 수 없다. 이러한 경우에 함수 기반 인덱스를 생성하면 이를 통해 해당 질의 처리를 최적화할 수 있다. 다른 예로, 대소문자를 구분하지 않는 이름을 검색할 때 활용할 수 있다.
CREATE /*+ hints */ INDEX index_name
ON table_name (function_name (argument_list));
ALTER /*+ hints */ INDEX index_name
[ ON table_name (function_name (argument_list)) ]
REBUILD;
다음 인덱스가 생성된 이후 SELECT 질의는 자동으로 함수 기반 인덱스를 사용한다.
CREATE INDEX idx_trim_post ON posts_table(TRIM(keyword));
SELECT *
FROM posts_table
WHERE TRIM(keyword) = 'SQL';
LOWER 함수로 함수 기반 인덱스를 생성하면, 대소문자 구분을 안 하는 이름을 검색할 때 사용될 수 있다.
CREATE INDEX idx_last_name_lower ON clients_table(LOWER(LastName));
SELECT *
FROM clients_table
WHERE LOWER(LastName) = LOWER('Timothy');
질의 계획을 생성할 때 인덱스가 선택되게 하기 위해서는, 이 인덱스에서 사용되는 함수가 질의 조건에서 같은 방법으로 사용되어야 한다. 위의 SELECT 질의는 위에서 생성된 last_name_lower 인덱스를 사용한다. 하지만 다음과 같은 조건에서는 함수 기반 인덱스 형태와 다른 표현식이 주어졌기 때문에 인덱스가 사용되지 않는다.
SELECT *
FROM clients_table
WHERE LOWER(CONCAT('Mr. ', LastName)) = LOWER('Mr. Timothy');
함수 기반 인덱스의 사용을 강제하려면 USING INDEX 구문을 사용할 수 있다.
CREATE INDEX i_tbl_first_four ON tbl(LEFT(col, 4));
SELECT *
FROM clients_table
WHERE LEFT(col, 4) = 'CAT5'
USING INDEX i_tbl_first_four;
함수 기반 인덱스로 사용할 수 있는 함수는 다음과 같다.
ABS
ACOS
ADD_MONTHS
ADDDATE
ASIN
ATAN
ATAN2
BIT_COUNT
BIT_LENGTH
CEIL
CHAR_LENGTH
CHR
COS
COT
DATE
DATE_ADD
DATE_FORMAT
DATE_SUB
DATEDIFF
DAY
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
DEGREES
EXP
FLOOR
FORMAT
FROM_DAYS
FROM_UNIXTIME
GREATEST
HOUR
IFNULL
INET_ATON
INET_NTOA
INSTR
LAST_DAY
LEAST
LEFT
LN
LOCATE
LOG
LOG10
LOG2
LOWER
LPAD
LTRIM
MAKEDATE
MAKETIME
MD5
MID
MINUTE
MOD
MONTH
MONTHS_BETWEEN
NULLIF
NVL
NVL2
OCTET_LENGTH
POSITION
POWER
QUARTER
RADIANS
REPEAT
REPLACE
REVERSE
RIGHT
ROUND
RPAD
RTRIM
SECOND
SECTOTIME
SIN
SQRT
STR_TO_DATE
STRCMP
SUBDATE
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TAN
TIME
TIME_FORMAT
TIMEDIFF
TIMESTAMP
TIMETOSEC
TO_CHAR
TO_DATE
TO_DATETIME
TO_DAYS
TO_NUMBER
TO_TIME
TO_TIMESTAMP
TRANSLATE
TRIM
TRUNC
UNIX_TIMESTAMP
UPPER
WEEK
WEEKDAY
YEAR
함수 기반 인덱스에서 사용할 함수의 인자는 테이블의 칼럼 이름 혹은 상수인 경우만 허용하며, 복잡한 중첩된 표현식은 허용하지 않는다. 예를 들어 아래의 문장은 오류를 발생한다.
CREATE INDEX my_idx ON tbl (TRIM(LEFT(col, 3)));
CREATE INDEX my_idx ON tbl (LEFT(col1, col2 + 3));
묵시적인 타입 변환(implicit type cast)은 허용된다. 아래의 예에서 LEFT() 함수는 첫 번째 인자 타입이 VARCHAR 이고 두 번째 인자 타입이 INTEGER 여야 하지만 정상 동작한다.
CREATE INDEX my_idx ON tbl (LEFT(int_col, str_col));
함수 기반 인덱스는 필터링된 인덱스와 함께 사용될 수 없다. 아래의 예는 오류를 발생한다.
CREATE INDEX my_idx ON tbl (TRIM(col)) WHERE col > 'SQL';
함수 기반 인덱스는 다중 칼럼 인덱스가 될 수 없다. 아래의 예는 오류를 발생한다.
CREATE INDEX my_idx ON tbl (TRIM(col1), col2, LEFT(col3, 5));
인덱스를 활용한 최적화
커버링 인덱스
질의 수행 시 SELECT 리스트, WHERE, HAVING, GROUP BY, ORDER BY 절에 있는 모든 칼럼의 데이터를 포함하는 인덱스를 커버링 인덱스(covering index)라고 한다.
커버링 인덱스는 질의 수행 시 인덱스 내에 필요한 모든 데이터를 지니고 있어서 인덱스 페이지만 검색하면 되며, 데이터 저장소를 추가로 검색할 필요가 없어 데이터 저장소 접근을 위한 I/O 비용을 줄일 수 있다. 데이터 검색 속도를 향상시키기 위해 커버링 인덱스로 생성하는 것을 고려할 수 있지만, 인덱스의 크기가 커지면 INSERT 와 DELETE 작업은 느려질 수 있다는 점을 감안해야 한다.
커버링 인덱스의 적용 여부에 대한 규칙은 다음과 같다.
CUBRID 질의 최적화기는 커버링 인덱스의 적용이 가능하면 이를 가장 먼저 사용한다.
조인 질의의 경우 인덱스가 SELECT 리스트에 있는 테이블의 칼럼을 포함하면, 이 인덱스를 사용한다.
인덱스를 사용할 수 있는 조건이 아닌 경우 커버링 인덱스를 사용할 수 없다.
CREATE TABLE t (col1 INT, col2 INT, col3 INT);
CREATE INDEX i_t_col1_col2_col3 ON t (col1,col2,col3);
INSERT INTO t VALUES (1,2,3),(4,5,6),(10,8,9);
다음의 예는 SELECT 하는 칼럼과 WHERE 조건의 칼럼이 모두 인덱스 내에 존재하므로, 해당 인덱스가 커버링 인덱스로 사용된다.
-- csql> ;plan simple
SELECT * FROM t WHERE col1 < 6;
Query plan:
Index scan(t t, i_t_col1_col2_col3, [(t.col1 range (min inf_lt t.col3))] (covers))
col1 col2 col3
=======================================
1 2 3
4 5 6
경고
VARCHAR 타입의 칼럼에서 값을 가져올 때 커버링 인덱스가 적용되는 경우, 뒤에 따라오는 공백 문자열은 잘리게 된다. 질의 최적화 수행 시 커버링 인덱스가 적용되면 질의 결과 값을 인덱스에서 가져오는데, 인덱스에는 뒤이어 나타나는 공백 문자열을 제거한 채로 값을 저장하기 때문이다.
이러한 현상을 원하지 않는다면 커버링 인덱스 기능을 사용하지 않도록 하는 NO_COVERING_IDX 힌트를 사용한다. 이 힌트를 사용하면 결과값을 인덱스 영역이 아닌 데이터 영역에서 가져오도록 한다.
다음은 위의 상황의 자세한 예이다. 먼저 VARCHAR 타입의 칼럼을 갖는 테이블을 생성하고, 여기에 시작 문자열의 값이 같고 문자열 뒤에 따르는 공백 문자의 개수가 다른 값을 INSERT 한다. 그리고 해당 칼럼에 인덱스를 생성한다.
CREATE TABLE tab(c VARCHAR(32));
INSERT INTO tab VALUES('abcd'),('abcd '),('abcd ');
CREATE INDEX i_tab_c ON tab(c);
인덱스를 반드시 사용하도록(커버링 인덱스가 적용되도록) 했을 때의 질의 결과는 다음과 같다.
-- csql>;plan simple
SELECT * FROM tab WHERE c='abcd ' USING INDEX i_tab_c(+);
Query plan:
Index scan(tab tab, i_tab_c, (tab.c='abcd ') (covers))
c
======================
'abcd'
'abcd'
'abcd'
다음은 인덱스를 사용하지 않도록 했을 때의 질의 결과이다.
SELECT * FROM tab WHERE c='abcd ' USING INDEX tab.NONE;
Query plan:
Sequential scan(tab tab)
c
======================
'abcd'
'abcd '
'abcd '
위의 두 결과 비교에서 알 수 있듯이, 커버링 인덱스가 적용되면 VARCHAR 타입에서는 인덱스로부터 값을 가져오면서 뒤이어 나타나는 공백 문자열이 잘린 채로 나타난다.
참고
커버링 인덱스 최적화가 적용될 수 있으면 디스크 입출력을 상당히 줄일 수 있기 때문에 성능 향상을 기대할 수 있다. 하지만 특정한 상황에서 커버링 인덱스 스캔 최적화를 원하지 않는다면, 질의에 NO_COVERING_IDX 힌트를 명시하면 된다. 힌트를 지정하는 방법은 SQL 힌트를 참고하면 된다.
ORDER BY 절 최적화
ORDER BY 절에 있는 모든 칼럼을 포함하는 인덱스를 정렬된 인덱스(ordered index)라고 한다. ORDER BY 절이 있는 질의를 최적화하면 정렬된 인덱스를 통해 질의 결과를 탐색하므로 별도의 정렬 과정을 거치지 않는다(skip order by). 정렬된 인덱스가 되기 위한 일반적인 조건은 ORDER BY 절에 있는 칼럼들이 인덱스의 가장 앞부분에 위치하는 경우이다.
SELECT *
FROM tab
WHERE col1 > 0
ORDER BY col1, col2;
tab (col1, col2) 으로 구성된 인덱스는 정렬된 인덱스이다.
tab (col1, col2, col3) 으로 구성된 인덱스도 정렬된 인덱스이다. ORDER BY 절에서 참조하지 않는 col3 는 col1, col2 뒤에 오기 때문이다.
tab (col1) 으로 구성된 인덱스는 정렬된 인덱스가 아니다.
tab (col3, col1, col2) 혹은 tab (col1, col3, col2)로 구성된 인덱스는 최적화에 사용할 수 없다. 이는 col3 가 ORDER BY 절의 칼럼들 뒤에 위치하지 않기 때문이다.
인덱스를 구성하는 칼럼이 ORDER BY 절에 없더라도 그 칼럼의 조건이 상수일 때는 정렬된 인덱스의 사용이 가능하다.
SELECT *
FROM tab
WHERE col2=val
ORDER BY col1,col3;
tab (col1, col2, col3)로 구성된 인덱스가 존재하고 tab (col1, col2)로 구성된 인덱스는 없이 위의 질의를 수행할 때, 질의 최적화기는 tab (col1, col2, col3)로 구성된 인덱스를 정렬된 인덱스로 사용한다. 즉, 인덱스 스캔 시 요구하는 순서대로 결과를 가져오므로, 레코드를 정렬할 필요가 없다.
정렬된 인덱스와 커버링 인덱스를 함께 사용할 수 있으면 커버링 인덱스를 먼저 사용한다. 커버링 인덱스를 사용하면 요청한 데이터의 결과가 인덱스 페이지에 모두 들어 있어 추가적인 데이터를 검색할 필요가 없으며, 이 인덱스가 순서까지 만족한다면, 결과를 정렬할 필요가 없기 때문이다.
질의가 조건을 포함하지 않으며 정렬된 인덱스를 사용할 수 있다면, 인덱스의 첫 번째 칼럼이 NOT NULL 조건을 만족한다는 전제 하에서는 정렬된 인덱스가 사용될 것이다.
CREATE TABLE tab (i INT, j INT, k INT);
CREATE INDEX i_tab_j_k on tab (j, k);
INSERT INTO tab VALUES (1,2,3), (6,4,2), (3,4,1), (5,2,1), (1,5,5), (2,6,6), (3,5,4);
다음의 예는 j, k 칼럼으로 ORDER BY 를 수행하므로 tab (j, k)로 구성된 인덱스는 정렬된 인덱스가 되고 별도의 정렬 과정을 거치지 않는다.
SELECT i,j,k
FROM tab
WHERE j > 0
ORDER BY j,k;
-- the selection from the query plan dump shows that the ordering index i_tab_j_k was used and sorting was not necessary
-- (/* --> skip ORDER BY */)
Query plan:
iscan
class: tab node[0]
index: i_tab_j_k term[0]
sort: 2 asc, 3 asc
cost: 1 card 0
Query stmt:
select tab.i, tab.j, tab.k from tab tab where ((tab.j> ?:0 )) order by 2, 3
/* ---> skip ORDER BY */
i j k
=======================================
5 2 1
1 2 3
3 4 1
6 4 2
3 5 4
1 5 5
2 6 6
다음의 예는 j, k 칼럼으로 ORDER BY 를 수행하며 SELECT 하는 칼럼을 모두 포함하는 인덱스가 존재하므로 tab(j,k)로 구성된 인덱스가 커버링 인덱스로서 사용된다. 따라서 인덱스 자체에서 값을 가져오게 되며 별도의 정렬 과정을 거치지 않는다.
SELECT /*+ RECOMPILE */ j,k
FROM tab
WHERE j > 0
ORDER BY j,k;
-- in this case the index i_tab_j_k is a covering index and also respects the ordering index property.
-- Therefore, it is used as a covering index and sorting is not performed.
Query plan:
iscan
class: tab node[0]
index: i_tab_j_k term[0] (covers)
sort: 1 asc, 2 asc
cost: 1 card 0
Query stmt: select tab.j, tab.k from tab tab where ((tab.j> ?:0 )) order by 1, 2
/* ---> skip ORDER BY */
j k
==========================
2 1
2 3
4 1
4 2
5 4
5 5
6 6
다음의 예는 i 칼럼 조건이 있으며 j, k 칼럼으로 ORDER BY 를 수행하고, SELECT 하는 칼럼이 i, j, k 이므로 tab (i, j, k)로 구성된 인덱스가 커버링 인덱스로서 사용된다. 따라서 인덱스 자체에서 값을 가져오게 되지만, ORDER BY j, k 에 대한 별도의 정렬 과정을 거친다.
CREATE INDEX i_tab_j_k ON tab (i,j,k);
SELECT /*+ RECOMPILE */ i,j,k
FROM tab
WHERE i > 0
ORDER BY j,k;
-- since an index on (i,j,k) is now available, it will be used as covering index. However, sorting the results according to
-- the ORDER BY clause is needed.
Query plan:
temp(order by)
subplan: iscan
class: tab node[0]
index: i_tab_i_j_k term[0] (covers)
sort: 1 asc, 2 asc, 3 asc
cost: 1 card 1
sort: 2 asc, 3 asc
cost: 7 card 1
Query stmt: select tab.i, tab.j, tab.k from tab tab where ((tab.i> ?:0 )) order by 2, 3
i j k
=======================================
5 2 1
1 2 3
3 4 1
6 4 2
3 5 4
1 5 5
2 6 6
참고
CAST() 연산자 등을 통해 ORDER BY 절의 칼럼이 타입 변환되더라도, 타입 변환 전의 정렬 순서와 타입 변환 이후의 정렬 순서가 같다면 ORDER BY 절 최적화가 수행된다.
변환 전
변환 이후
수치형 타입
수치형 타입
문자열 타입
문자열 타입
DATETIME
TIMESTAMP
TIMESTAMP
DATETIME
DATETIME
DATE
TIMESTAMP
DATE
DATE
DATETIME
내림차순 인덱스 스캔
다음과 같이 내림차순 정렬이 있는 질의를 수행할 때 일반적으로 내림차순 인덱스를 생성하여 인덱스를 사용하도록 하면 별도의 정렬 과정이 필요 없다.
SELECT *
FROM tab
[WHERE ...]
ORDER BY a DESC;
그런데 같은 칼럼에 대해 오름차순 인덱스와 내림차순 인덱스를 생성하면 교착 상태(deadlock)의 발생 가능성이 높아진다. 이러한 경우를 줄이기 위해 CUBRID는 별도의 내림차순 인덱스를 생성하지 않아도, 오름차순 인덱스만으로 내림차순 인덱스 스캔을 사용할 수 있다. 사용자는 USE_DESC_IDX 힌트를 사용하여 내림차순 스캔을 사용하도록 명시할 수 있다. 이 힌트가 명시되지 않으면 ORDER BY 절에 나열된 칼럼이 인덱스를 사용할 수 있다는 전제 조건 하에서 아래의 3가지 질의 실행 계획을 고려할 수 있다.
순차 스캔 + 내림차순 정렬
일반적인 오름차순 스캔 + 내림차순 정렬
별도의 정렬 작업이 필요 없는 내림차순 스캔
내림차순 스캔을 위해 USE_DESC_IDX 힌트가 생략된다 하더라도 질의 최적화기는 위에서 나열한 3가지 중 제일 마지막 실행 계획을 최적의 계획으로 결정한다.
참고
USE_DESC_IDX 힌트는 조인 질의에 대해서는 지원하지 않는다.
CREATE TABLE di (i INT);
CREATE INDEX i_di_i on di (i);
INSERT INTO di VALUES (5),(3),(1),(4),(3),(5),(2),(5);
다음 예는 USE_DESC_IDX 힌트 없이 오름차순 스캔을 통해 질의를 수행한다.
-- The query will be executed with an ascending scan.
SELECT *
FROM di
WHERE i > 0
LIMIT 3;
Query plan:
Index scan(di di, i_di_i, (di.i range (0 gt_inf max) and inst_num() range (min inf_le 3)) (covers))
i
=============
1
2
3
위의 질의에 USE_DESC_IDX 힌트를 추가하면 내림차순 스캔을 통해 다른 결과가 나온다.
-- We now run the same query, using the 'use_desc_idx' SQL hint:
SELECT /*+ USE_DESC_IDX */ *
FROM di
WHERE i > 0
LIMIT 3;
Query plan:
Index scan(di di, i_di_i, (di.i range (0 gt_inf max) and inst_num() range (min inf_le 3)) (covers) (desc_index))
i
=============
5
5
5
다음 예는 ORDER BY 절을 통해 내림차순 정렬이 요구되는 경우이다. 이 경우 USE_DESC_IDX 힌트가 없지만 내림차순 스캔하게 된다.
-- We also run the same query, this time asking that the results are displayed in descending order.
-- However, no hint is given.
-- Since ORDER BY...DESC clause exists, CUBRID will use descending scan, even though the hint is not given,
-- thus avoiding to sort the records.
SELECT *
FROM di
WHERE i > 0
ORDER BY i DESC LIMIT 3;
Query plan:
Index scan(di di, i_di_i, (di.i range (0 gt_inf max)) (covers) (desc_index))
i
=============
5
5
5
GROUP BY 절 최적화
GROUP BY 절에 있는 모든 칼럼이 인덱스에 포함되어 질의 수행 시 인덱스를 사용할 수 있으므로 별도의 정렬 작업을 하지 않는 것을 GROUP BY 절 최적화라고 한다. 이를 위해서는 GROUP BY 절에 있는 칼럼들이 인덱스를 구성하는 칼럼들의 제일 앞 쪽에 모두 존재해야 한다.
SELECT *
FROM tab
WHERE col1 > 0
GROUP BY col1,col2;
tab (col1, col2)로 구성된 인덱스는 최적화에 사용할 수 있다.
tab (col1, col2, col3)로 구성된 인덱스도 사용될 수 있는데, GROUP BY 절에서 참조하지 않는 col3 는 col1, col2 뒤에 오기 때문이다.
tab (col1)로 구성된 인덱스는 최적화에 사용할 수 없다.
tab (col3, col1, col2) 혹은 tab (col1, col3, col2)로 구성된 인덱스도 최적화에 사용할 수 없는데, col3 가 GROUP BY 절의 칼럼들 뒤에 위치하지 않기 때문이다.
인덱스를 구성하는 칼럼이 GROUP BY 절에 없더라도 그 칼럼의 조건이 상수일 때는 인덱스를 사용할 수 있다.
SELECT *
FROM tab
WHERE col2=val
GROUP BY col1,col3;
위의 예에서 tab (col1, col2, col3)로 구성된 인덱스가 있으면 이 인덱스를 GROUP BY 최적화에 사용한다.
이 경우에도 인덱스 스캔 시 요구하는 순서대로 결과를 가져오므로, GROUP BY 에 의해서 행에 대한 정렬이 불필요하게 된다.
WHERE 절이 없어도 GROUP BY 칼럼으로 구성된 인덱스가 있고 그 인덱스의 첫번째 칼럼이 NOT NULL 이면 GROUP BY 최적화가 적용된다.
집계 함수 사용 시에도 GROUP BY 칼럼으로 구성된 인덱스가 있으면 GROUP BY 최적화가 적용된다.
CREATE INDEX i_T_a_b_c ON T(a, b, c);
SELECT a, MIN(b), c, MAX(b) FROM T WHERE a > 18 GROUP BY a, b;
참고
GROUP BY 절 또는 DISTINCT의 칼럼이 인덱스 부분 키(subkey)를 포함할 때, 부분 키를 구성하는 칼럼 각각의 고유(unique) 값에 대해 동적으로 범위를 조정하여 B-트리 검색을 시작한다. 이와 관련하여 Loose Index Scan을 참고한다.
예제
CREATE TABLE tab (i INT, j INT, k INT);
CREATE INDEX i_tab_j_k ON tab (j, k);
INSERT INTO tab VALUES (1,2,3), (6,4,2), (3,4,1), (5,2,1), (1,5,5), (2,6,6), (3,5,4);
UPDATE STATISTICS on tab;
다음의 예는 j, k 칼럼으로 GROUP BY 를 수행하므로 tab (j, k)로 구성된 인덱스가 사용되고 별도의 정렬 과정이 필요 없다.
SELECT /*+ RECOMPILE */ j,k
FROM tab
WHERE j > 0
GROUP BY j,k;
-- the selection from the query plan dump shows that the index i_tab_j_k was used and sorting was not necessary
-- (/* ---> skip GROUP BY */)
Query plan:
iscan
class: tab node[0]
index: i_tab_j_k term[0]
sort: 2 asc, 3 asc
cost: 1 card 0
Query stmt:
select tab.i, tab.j, tab.k from tab tab where ((tab.j> ?:0 )) group by tab.j, tab.k
/* ---> skip GROUP BY */
i j k
5 2 1
1 2 3
3 4 1
6 4 2
3 5 4
1 5 5
2 6 6
다음의 예는 j, k 칼럼으로 GROUP BY 를 수행하며 j 에 대한 조건이 없지만 j 칼럼은 NOT NULL 속성을 지니므로, tab (j, k)로 구성된 인덱스가 사용되고 별도의 정렬 과정이 필요 없다.
ALTER TABLE tab CHANGE COLUMN j j INT NOT NULL;
SELECT *
FROM tab
GROUP BY j,k;
-- the selection from the query plan dump shows that the index i_tab_j_k was used (since j has the NOT NULL constraint )
-- and sorting was not necessary (/* ---> skip GROUP BY */)
Query plan:
iscan
class: tab node[0]
index: i_tab_j_k
sort: 2 asc, 3 asc
cost: 1 card 0
Query stmt: select tab.i, tab.j, tab.k from tab tab group by tab.j, tab.k
/* ---> skip GROUP BY */
=== <Result of SELECT Command in Line 1> ===
i j k
=======================================
5 2 1
1 2 3
3 4 1
6 4 2
3 5 4
1 5 5
2 6 6
CREATE TABLE tab (k1 int, k2 int, k3 int, v double);
INSERT INTO tab
SELECT
RAND(CAST(UNIX_TIMESTAMP() AS INT)) MOD 5,
RAND(CAST(UNIX_TIMESTAMP() AS INT)) MOD 10,
RAND(CAST(UNIX_TIMESTAMP() AS INT)) MOD 100000,
RAND(CAST(UNIX_TIMESTAMP() AS INT)) MOD 100000
FROM db_class a, db_class b, db_class c, db_class d LIMIT 20000;
CREATE INDEX idx ON tab(k1, k2, k3);
위의 테이블과 인덱스를 생성했을 때 다음의 예는 k1, k2 칼럼으로 GROUP BY를 수행하며 k3로 집계 함수를 수행하므로 tab(k1, k2, k3)로 구성된 인덱스가 사용되고 별도의 정렬 과정이 필요 없다. 또한 SELECT 리스트에 있는 k1, k2, k3 칼럼이 모두 tab(k1, k2, k3)로 구성된 인덱스 내에 존재하므로 커버링 인덱스가 적용된다.
SELECT /*+ RECOMPILE INDEX_SS */ k1, k2, SUM(DISTINCT k3)
FROM tab
WHERE k2 > -1 GROUP BY k1, k2;
Query plan:
iscan
class: tab node[0]
index: idx term[0] (covers) (index skip scan)
sort: 1 asc, 2 asc
cost: 85 card 2000
Query stmt:
select tab.k1, tab.k2, sum(distinct tab.k3) from tab tab where (tab.k2> ?:0 ) group by tab.k1, tab.k2
/* ---> skip GROUP BY */
다음의 예는 k1, k2 칼럼으로 GROUP BY를 수행하므로 tab*(*k1, k2, k3)로 구성된 인덱스가 사용되고 별도의 정렬 과정이 필요 없다. 하지만 SELECT 리스트에 있는 v 칼럼은 tab*(*k1, k2, k3)로 구성된 인덱스 내에 존재하지 않으므로 커버링 인덱스가 적용되지 않는다.
SELECT /*+ RECOMPILE INDEX_SS */ k1, k2, stddev_samp(v)
FROM tab
WHERE k2 > -1 GROUP BY k1, k2;
Query plan:
iscan
class: tab node[0]
index: idx term[0] (index skip scan)
sort: 1 asc, 2 asc
cost: 85 card 2000
Query stmt:
select tab.k1, tab.k2, stddev_samp(tab.v) from tab tab where (tab.k2> ?:0 ) group by tab.k1, tab.k2
/* ---> skip GROUP BY */
다중 키 범위 최적화
대부분의 질의가 LIMIT 절을 포함하고 있기 때문에 LIMIT 절을 최적화하는 것이 질의 성능에 매우 중요한데, 이에 해당하는 대표적인 최적화가 다중 키 범위 최적화(multiple key range optimization)이다.
다중 키 범위 최적화는 결과 생성에 필요한 인덱스 범위 전체를 스캔하지 않고, 인덱스 내의 일부 키 범위만 스캔하면서 Top N 정렬 방식을 통해 질의 결과를 생성한다. Top N 정렬은 전체 결과를 생성한 후에 이를 정렬하여 결과를 얻는 것이 아니라, 항상 최적의 N 개의 결과를 유지하는 방식으로 질의를 처리하기 때문에 매우 뛰어난 성능을 보인다.
예를 들어 내 친구들이 쓴 글 중에서 가장 최근 글을 10 개만 검색하는 경우, 다중 키 범위 최적화가 적용되면 내 전체 친구가 쓴 글을 모두 찾아서 정렬한 후에 결과를 찾지 않고 각 친구가 쓴 최근 글 10 개씩만을 찾아서 정렬을 유지하고 있는 인덱스를 스캔하여 결과를 찾는다.
다중 키 범위 최적화를 사용할 수 있는 예는 다음과 같다.
CREATE TABLE t (a int, b int);
CREATE INDEX i_t_a_b ON t (a,b);
-- Multiple key range optimization
SELECT *
FROM t
WHERE a IN (1,2,3)
ORDER BY b
LIMIT 2;
Query plan:
iscan
class: t node[0]
index: i_t_a_b term[0] (covers) (multi_range_opt)
sort: 1 asc, 2 asc
cost: 1 card 0
단일 테이블에서는 다음과 같은 조건들이 만족되었을 경우에 다중 키 범위 최적화가 수행된다.
SELECT /*+ hints */ ...
FROM table
WHERE col_1 = ? AND col_2 = ? AND ... AND col(j-1) = ?
AND col_(j) IN (?, ?, ...)
AND col_(j+1) = ? AND ... AND col_(p-1) = ?
AND key_filter_terms
ORDER BY col_(p) [ASC|DESC], col_(p+1) [ASC|DESC], ... col_(p+k-1) [ASC|DESC]
LIMIT n;
먼저 LIMIT 절을 통해서 지정된 최종 결과의 상한 크기(n)가 multi_range_optimization_limit 시스템 파라미터 값보다 작거나 같아야 한다.
또한 다중 키 범위 최적화에 적합한 인덱스가 필요한데, ORDER BY 절에 명시된 모든 k 개의 칼럼을 커버해야 한다. 즉, 인덱스 상에서 ORDER BY 절에 명시된 칼럼들을 모두 포함해야 하고, 칼럼들의 순서와 정렬 방향이 일치해야 한다. 또한 WHERE 절에서 사용되는 모든 칼럼을 포함해야 한다.
인덱스를 구성하는 칼럼들 중
범위 조건(예를 들어, IN 조건) 앞의 칼럼들은 동일(=) 조건으로 표현된다.
범위 조건을 가진 칼럼이 하나만 존재한다.
범위 조건 이후의 칼럼들은 키 필터로 존재한다.
데이터 필터 조건이 없어야 한다. 다시 말해, 인덱스는 WHERE 절에서 사용되는 모든 칼럼을 포함해야 한다.
키 필터 이후의 칼럼들은 ORDER BY 절에 존재한다.
키 필터 조건의 칼럼들은 반드시 ORDER BY 절의 칼럼이 아니어야 한다.
상관 부질의(correlated subquery)를 포함한 키 필터 조건이 포함되어 있다면, 이에 연관된 칼럼은 범위 조건이 아닌 조건으로 WHERE 절에 포함되어야 한다.
다음과 같은 예에 다중 키 범위 최적화가 수행된다.
CREATE TABLE t (a INT, b INT, c INT, d INT, e INT);
CREATE INDEX i_t_a_b ON t (a,b,c,d,e);
SELECT *
FROM t
WHERE a = 1 AND b = 3 AND c IN (1,2,3) AND d = 3
ORDER BY e
LIMIT 2;
다중 테이블을 포함하는 JOIN 질의에서는 다음의 경우 최적화가 수행된다.
SELECT /*+ hints */ ...
FROM table_1, table_2, ... table_(sort), ...
WHERE col_1 = ? AND col_2 = ? AND ...
AND col_(j) IN (?, ?, ... )
AND col_(j+1) = ? AND ... AND col_(p-1) = ?
AND key_filter_terms
AND join_terms
ORDER BY col_(p) [ASC|DESC], col_(p+1) [ASC|DESC], ... col_(p+k-1) [ASC|DESC]
LIMIT n;
JOIN 질의에 대해서 다중 키 범위 최적화가 적용되기 위해서는 다음과 같은 조건을 만족해야 한다.
ORDER BY 절에 존재하는 칼럼들은 하나의 테이블에만 존재하는 칼럼들이며, 이 테이블은 단일 테이블 질의에서 다중 키 범위 최적화에 의해 요구되는 조건을 모두 만족해야 한다. 이 테이블을 정렬 테이블(sort table)이라고 하자.
정렬 테이블과 외부 테이블들(outer tables) 간의 JOIN 조건에 명시된 정렬 테이블의 칼럼들은 모두 인덱스에 포함되어야 한다. 즉, 데이터 필터링 조건이 없어야 한다.
정렬 테이블과 내부 테이블들(inner tables) 간의 JOIN 조건에 명시된 정렬 테이블의 칼럼들은 범위 조건이 아닌 조건으로 WHERE 절에 포함되어야 한다.
참고
다중 키 범위 최적화가 적용될 수 있는 대부분의 경우에 다중 키 범위 최적화가 가장 좋은 성능을 보장하지만, 특정한 상황에서 최적화를 원하지 않는다면 질의에 NO_MULTI_RANGE_OPT 힌트를 명시하면 된다. 힌트를 지정하는 방법은 SQL 힌트를 참고하면 된다.
Index Skip Scan
Index Skip Scan(이하 ISS)은 인덱스의 첫 번째 칼럼이 조건에 명시되지 않아도 뒤따라오는 칼럼이 조건(주로 =)에 명시되면 해당 인덱스를 활용하여 질의를 처리하는 최적화 방식이다.
질의문 힌트를 통해 특정 테이블에 대한 INDEX_SS가 입력되고 다음의 경우를 만족할 때 ISS의 적용이 고려된다.
복합 인덱스의 두번째 칼럼부터 조건에 명시된다.
사용되는 인덱스가 필터링된 인덱스가 아니어야 한다.
인덱스의 첫 번째 칼럼이 범위 필터나 키 필터가 아니어야 한다.
계층 질의는 지원하지 않는다.
집계 함수가 포함된 경우는 지원하지 않는다.
INDEX_SS 힌트에는 ISS의 적용을 고려할 테이블 리스트를 입력할 수 있으며, 테이블 리스트가 생략되는 경우 모든 테이블에 대해 ISS의 적용이 고려된다.
/*+ INDEX_SS */
/*+ INDEX_SS(tbl1) */
/*+ INDEX_SS(tbl1, tbl2) */
참고
“INDEX_SS”를 입력하면 모든 테이블에 ISS 힌트가 적용되지만, “INDEX_SS()”를 입력하면 힌트가 무시된다.
CREATE TABLE t1 (id INT PRIMARY KEY, a INT, b INT, c INT);
CREATE TABLE t2 (id INT PRIMARY KEY, a INT, b INT, c INT);
CREATE INDEX i_t1_ac ON t1(a,c);
CREATE INDEX i_t2_ac ON t2(a,c);
INSERT INTO t1 SELECT rownum, rownum, rownum, rownum
FROM db_class x1, db_class x2, db_class LIMIT 10000;
INSERT INTO t2 SELECT id, a%5, b, c FROM t1;
SELECT /*+ INDEX_SS */ *
FROM t1, t2
WHERE t1.b<5 AND t1.c<5 AND t2.c<5
USING INDEX i_t1_ac, i_t2_ac limit 1;
SELECT /*+ INDEX_SS(t1) */ *
FROM t1, t2
WHERE t1.b<5 AND t1.c<5 AND t2.c<5
USING INDEX i_t1_ac, i_t2_ac LIMIT 1;
SELECT /*+ INDEX_SS(t1, t2) */ *
FROM t1, t2
WHERE t1.b<5 AND t1.c<5 AND t2.c<5
USING INDEX i_t1_ac, i_t2_ac LIMIT 1;
일반적으로 ISS는 여러 개의 칼럼들(C1, C2, …, Cn) 중에서 고려되어야 하는데, 여기에서 질의는 연속된 칼럼들에 대한 조건을 가지고 있고 이 조건들은 인덱스의 두 번째 칼럼(C2)부터 시작한다.
INDEX (C1, C2, ..., Cn);
SELECT ... WHERE C2 = x AND C3 = y AND ... AND Cp = z; -- p <= n
SELECT ... WHERE C2 < x AND C3 >= y AND ... AND Cp BETWEEN (z AND w); -- other conditions than equal
질의 최적화기는 궁극적으로 비용에 따라 ISS가 최적의 접근 방식인지 비용을 감안하여 결정한다. ISS는 인덱스의 첫 번째 칼럼이 레코드 개수에 비해 고유한(DISTINCT) 값의 개수가 적은 경우와 같이 특정한 상황에서 적용되며, 이 경우 인덱스 전체 검색(index full scan)보다 더 우수한 성능을 발휘한다. 예를 들어, 인덱스 칼럼 중에 첫 번째 칼럼이 남성/여성의 값 또는 수백만 건의 레코드가 1~100 사이의 값을 가지는 것처럼 DISTINCT 값의 개수가 매우 낮고(값의 중복도가 높고), 이 칼럼 조건이 질의 조건에 명시되지 않은 경우에 질의 최적화기는 ISS 적용을 검토하게 된다.
인덱스 전체 검색은 인덱스 리프 전체를 모두 다 읽어야 하지만, ISS는 동적으로 재조정되는 범위 검색(range search)을 사용하여 대부분의 인덱스 페이지 읽기를 생략하면서 질의를 처리한다. 값의 중복도가 높을수록 읽기를 생략할 수 있는 인덱스 페이지가 많아질 수 있기 때문에 ISS의 효율이 높아질 수 있다. 하지만 ISS가 많이 적용된다는 것은 인덱스 생성이 적절하지 않다는 것을 의미하기 때문에, DBA들은 인덱스 재조정이 필요하지 않은지 검토해볼 필요가 있다.
CREATE TABLE tbl (name STRING, gender CHAR (1), birthday DATETIME);
INSERT INTO tbl
SELECT ROWNUM, CASE (ROWNUM MOD 2) WHEN 1 THEN 'M' ELSE 'F' END, SYSDATETIME
FROM db_class a, db_class b, db_class c, db_class d, db_class e LIMIT 360000;
CREATE INDEX idx_tbl_gen_name ON tbl (gender, name);
-- Note that gender can only have 2 values, 'M' and 'F' (low cardinality)
UPDATE STATISTICS ON ALL CLASSES;
-- csql>;plan simple
-- this will qualify to use Index Skip Scanning
SELECT /*+ RECOMPILE INDEX_SS */ *
FROM tbl
WHERE name = '1000';
Query plan:
Index scan(tbl tbl, idx_tbl_gen_name, tbl.[name]= ?:0 (index skip scan))
-- csql>;plan simple
-- this will qualify to use Index Skip Scanning
SELECT /*+ RECOMPILE INDEX_SS */ *
FROM tbl
WHERE name between '1000' and '1050';
Query plan:
Index scan(tbl tbl, idx_tbl_gen_name, (tbl.[name]>= ?:0 and tbl.[name]<= ?:1 ) (index skip scan))
Loose Index Scan
GROUP BY 절 또는 DISTINCT의 칼럼이 인덱스 부분 키(subkey)를 포함할 때, loose index scan은 부분 키를 구성하는 칼럼 각각의 고유(unique) 값에 대해 동적으로 범위를 조정하여 B-트리 검색을 시작한다. 따라서 B-트리의 스캔 영역을 상당 부분 줄일 수 있다.
Loose index scan은 그룹핑되는 칼럼의 카디널리티가 전체 데이터량이 비해 매우 작을 때 적용하는 것이 유리하다.
질의문 힌트를 통해 INDEX_LS가 입력되고 다음의 경우에 loose index scan의 적용이 고려된다.
인덱스가 SELECT 리스트의 모든 부분을 커버하는 경우. 즉, 커버링 인덱스가 적용되는 경우
SELECT DISTINCT, SELECT … GROUP BY 또는 단일 투플 SELECT 문인 경우
MIN/MAX 함수를 제외한 모든 집계 함수가 DISTINCT 를 포함하는 경우
COUNT(*) 가 사용되어선 안 됨
부분 키(subkey)의 카디널리티(고유 값의 개수)가 전체 인덱스의 카디널리티보다 100배 작은 경우
부분 키는 복합 인덱스(composite index)에서 앞 쪽 부분에 해당하는 것으로, 예를 들어 INDEX(a, b, c, d)로 구성되어 있는 경우 (a), (a, b) 또는 (a, b, c)가 부분 키에 해당한다.
이상과 같이 구성된 테이블에 대해 다음 질의를 수행하는 경우,
SELECT /*+ INDEX_LS */ a, b FROM tbl GROUP BY a;
칼럼 a에 대한 조건이 없으므로 부분 키를 사용할 수 없다. 그러나 다음과 같이 부분 키의 조건이 명시되면 loose index scan이 적용될 수 있다.
SELECT /*+ INDEX_LS */ a, b FROM tbl WHERE a > 10 GROUP BY a;
다음과 같이 그룹핑 칼럼이 앞에, WHERE 조건 칼럼이 뒤에 오는 경우에도 부분 키를 사용할 수 있으므로 loose index scan이 적용될 수 있다.
SELECT /*+ INDEX_LS */ a, b FROM tbl WHERE b > 10 GROUP BY a;
다음은 loose index scan이 적용되는 예이다.
CREATE TABLE tbl1 (
k1 INT,
k2 INT,
k3 INT,
k4 INT
);
INSERT INTO tbl1
SELECT ROWNUM MOD 2, ROWNUM MOD 400, ROWNUM MOD 80000, ROWNUM
FROM db_class a, db_class b, db_class c, db_class d, db_class e LIMIT 360000;
CREATE INDEX idx ON tbl1 (k1, k2, k3);
CREATE TABLE tbl2 (
k1 INT,
k2 INT
);
INSERT INTO tbl2 VALUES (0, 0), (1, 1), (0, 2), (1, 3), (0, 4), (0, 100), (1000, 1000);
UPDATE STATISTICS ON ALL CLASSES;
-- csql>;plan simple
-- add a condition to the grouped column, k1 to enable loose index scan
SELECT /*+ RECOMPILE INDEX_LS */ DISTINCT k1
FROM tbl1
WHERE k1 > -1000000 LIMIT 20;
Query plan:
Sort(distinct)
Index scan(tbl1 tbl1, idx, (tbl1.k1> ?:0 ) (covers) (loose index scan on prefix 1))
-- csql>;plan simple
-- different key ranges/filters
SELECT /*+ RECOMPILE INDEX_LS */ DISTINCT k1
FROM tbl1
WHERE k1 >= 0 AND k1 <= 1;
Query plan:
Sort(distinct)
Index scan(tbl1 tbl1, idx, (tbl1.k1>= ?:0 and tbl1.k1<= ?:1 ) (covers) (loose index scan on prefix 1))
-- csql>;plan simple
SELECT /*+ RECOMPILE INDEX_LS */ DISTINCT k1, k2
FROM tbl1
WHERE k1 >= 0 AND k1 <= 1 AND k2 > 3 AND k2 < 11;
Query plan:
Sort(distinct)
Index scan(tbl1 tbl1, idx, (tbl1.k1>= ?:0 and tbl1.k1<= ?:1 ), [(tbl1.k2> ?:2 and tbl1.k2< ?:3 )] (covers) (loose index scan on prefix 2))
-- csql>;plan simple
SELECT /*+ RECOMPILE INDEX_LS */ DISTINCT k1, k2
FROM tbl1
WHERE k1 >= 0 AND k1 + k2 <= 10;
Query plan:
Sort(distinct)
Index scan(tbl1 tbl1, idx, (tbl1.k1>= ?:0 ), [tbl1.k1+tbl1.k2<=10] (covers) (loose index scan on prefix 2))
-- csql>;plan simple
SELECT /*+ RECOMPILE INDEX_LS */ tbl1.k1, tbl1.k2
FROM tbl2 INNER JOIN tbl1
ON tbl2.k1 = tbl1.k1 AND tbl2.k2 = tbl1.k2
GROUP BY tbl1.k1, tbl1.k2;
Sort(group by)
Nested loops
Sequential scan(tbl2 tbl2)
Index scan(tbl1 tbl1, idx, tbl2.k1=tbl1.k1 and tbl2.k2=tbl1.k2 (covers) (loose index scan on prefix 2))
SELECT /*+ RECOMPILE INDEX_LS */ MIN(k2), MAX(k2)
FROM tbl1;
Query plan:
Index scan(tbl1 tbl1, idx (covers) (loose index scan on prefix 2))
-- csql>;plan simple
SELECT /*+ RECOMPILE INDEX_LS */ SUM(DISTINCT k1), SUM(DISTINCT k2)
FROM tbl1;
Query plan:
Index scan(tbl1 tbl1, idx (covers) (loose index scan on prefix 2))
-- csql>;plan simple
SELECT /*+ RECOMPILE INDEX_LS */ DISTINCT k1
FROM tbl1
WHERE k2 > 0;
Query plan:
Sort(distinct)
Index scan(tbl1 tbl1, idx, [(tbl1.k2> ?:0 )] (covers) (loose index scan on prefix 2))
다음은 loose index scan이 적용되지 않는 경우이다.
-- csql>;plan simple
-- not enabled when full key is used
SELECT /*+ RECOMPILE INDEX_LS */ DISTINCT k1, k2, k3
FROM tbl1
ORDER BY 1, 2, 3 LIMIT 10;
Query plan:
Sort(distinct)
Sequential scan(tbl1 tbl1)
-- csql>;plan simple
SELECT /*+ RECOMPILE INDEX_LS */ k1, k2, k3
FROM tbl1
WHERE k1 > -10000 GROUP BY k1, k2, k3 LIMIT 10;
Query plan:
Index scan(tbl1 tbl1, idx, (tbl1.k1> ?:0 ) (covers))
skip GROUP BY
-- csql>;plan simple
-- not enabled when using count star
SELECT /*+ RECOMPILE INDEX_LS */ COUNT(*), k1
FROM tbl1
WHERE k1 > -10000 GROUP BY k1;
Query plan:
Index scan(tbl1 tbl1, idx, (tbl1.k1> ?:0 ) (covers))
skip GROUP BY
-- csql>;plan simple
-- not enabled when index is not covering
SELECT /*+ RECOMPILE INDEX_LS */ k1, k2, SUM(k4)
FROM tbl1
WHERE k1 > -1 AND k2 > -1 GROUP BY k1, k2 LIMIT 10;
Query plan:
Index scan(tbl1 tbl1, idx, (tbl1.k1> ?:0 ), [(tbl1.k2> ?:1 )])
skip GROUP BY
-- csql>;plan simple
-- not enabled for non-distinct aggregates
SELECT /*+ RECOMPILE INDEX_LS */ k1, SUM(k2)
FROM tbl1
WHERE k1 > -1 GROUP BY k1;
Query plan:
Index scan(tbl1 tbl1, idx, (tbl1.k1> ?:0 ) (covers))
skip GROUP BY
-- csql>;plan simple
SELECT /*+ RECOMPILE */ SUM(k1), SUM(k2)
FROM tbl1;
Query plan:
Sequential scan(tbl1 tbl1)
인-메모리 정렬
인-메모리 정렬(in memory sort, IMS) 기능은 ORDER BY 절을 명시한 LIMIT 질의에 적용되는 최적화이다. 일반적으로, ORDER BY 와 LIMIT 절을 명시한 질의를 수행할 때, CUBRID는 전체 정렬 결과셋(full sorted resultset) 생성하고 나서 이 결과 셋에 LIMIT 연산을 적용한다. 전체 결과셋을 생성하는 대신 IMS 최적화를 사용하면, CUBRID는 ORDER BY … LIMIT 절을 만족하는 투플만 정렬 버퍼(sort buffer)에 저장하는 인-메모리 바이너리 힙을 사용한다. 이 최적화는 정렬되지 않은 결과셋 전체를 정렬할 필요가 없게 하여 성능을 향상시킨다.
이 최적화의 적용 여부는 사용자가 제어하는 것이 아니며, CUBRID는 다음 상황에서 IMS를 사용할 것을 결정한다.
ORDER BY 와 LIMIT 절을 명시한 질의
LIMIT 절 적용 이후 최종 결과의 크기가 외부 정렬(external sort)에 의해 사용되는 메모리 양보다 작을 때(메모리 관련 파라미터의 sort_buffer_size 참고).
IMS는 결과 행의 개수가 아닌 결과의 실제 크기를 고려함에 주의한다. 예를 들어, 기본 정렬 버퍼 크기(2MB)에 대해, 4바이트 INTEGER 하나로 구성된 레코드는 524288개 행의 LIMIT 까지 IMS가 적용되지만 CHAR (1024) 하나로 구성된 레코드는 2048개 행의 LIMIT 까지만 IMS가 적용된다. 이 최적화는 DISTINCT 정렬 결과 셋을 요구하는 질의에는 적용되지 않는다.
SORT-LIMIT 최적화
SORT-LIMIT 최적화는 ORDER BY 절과 LIMIT 절을 명시한 질의에 적용되는 최적화이다. 이 최적화는 조인하는 동안의 카디널리티(cardinality)를 줄이기 위해 질의 계획에서 가능한 빨리 LIMIT 연산자를 평가하고자 한다.
다음 조건이 만족될 때 SORT-LIMIT 계획이 고려될 수 있다.
ORDER BY 절에서 참조되는 모든 테이블은 SORT-LIMIT 계획에 속한다.
JOIN 테이블 중 다음 테이블이 SORT-LIMIT 계획에 포함된다.
외래 키/기본 키 관계에서 외래 키를 가지는 테이블
LEFT JOIN 시 왼쪽 테이블
RIGHT JOIN 시 오른쪽 테이블
LIMIT 행은 sort_limit_max_count 시스템 파라미터(기본값: 1000) 값보다 작아야 한다.
질의가 CROSS JOIN을 하지 않는다.
질의가 최소한 2개의 릴레이션으로 조인한다.
질의는 GROUP BY 절을 가지지 않는다.
질의는 DISTINCT 를 명시하지 않는다.
ORDER BY 표현식이 스캔하는 동안 평가될 수 있다.
예를 들어, 아래와 같은 질의는 SORT-LIMIT 최적화가 적용될 수 없는데, SUM 은 스캔하는 동안 평가될 수 없기 때문이다.
SELECT SUM(u.i) FROM u, t where u.i = t.i ORDER BY 1 LIMIT 5;
다음은 SORT-LIMIT을 계획하는 예이다.
CREATE TABLE t(i int PRIMARY KEY, j int, k int);
CREATE TABLE u(i int, j int, k int);
ALTER TABLE u ADD constraint fk_t_u_i FOREIGN KEY(i) REFERENCES t(i);
CREATE INDEX i_u_j ON u(j);
INSERT INTO t SELECT ROWNUM, ROWNUM, ROWNUM FROM _DB_CLASS a, _DB_CLASS b LIMIT 1000;
INSERT INTO u SELECT 1+(ROWNUM % 1000), RANDOM(1000), RANDOM(1000) FROM _DB_CLASS a, _DB_CLASS b, _DB_CLASS c LIMIT 5000;
SELECT /*+ RECOMPILE */ * FROM u, t WHERE u.i = t.i AND u.j > 10 ORDER BY u.j LIMIT 5;
위의 SELECT 질의 계획이 아래와 같이 출력될 때 “(sort limit)”을 확인할 수 있다.
Query plan:
idx-join (inner join)
outer: temp(sort limit)
subplan: iscan
class: u node[0]
index: i_u_j term[1]
cost: 1 card 0
cost: 1 card 0
inner: iscan
class: t node[1]
index: pk_t_i term[0]
cost: 6 card 1000
sort: 2 asc
cost: 7 card 0