CUBRID SHARD¶
Database Sharding¶
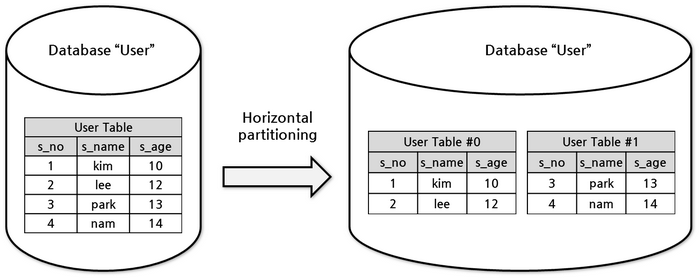
수평 분할
수평 분할(horizontal partitioning)이란 스키마가 동일한 데이터를 행을 기준으로 두 개 이상의 테이블에 나누어 저장하는 디자인을 말한다. 예를 들어 'User Table'을 동일 스키마의 13세 미만의 유저를 저장하는 'User Table #0'과 13세 이상의 유저를 저장하는 'User Table #1'로 분할하여 사용할 수 있다. 수평 분할로 인해 각 테이블의 데이터와 인덱스의 크기가 감소하고 작업 동시성이 늘어 성능 향상을 기대할 수 있다. 수평 분할은 일반적으로 하나의 테이터베이스 안에서 이루어진다. 수평 분할로 인해 각 테이블의 데이터와 인덱스의 크기가 감소하기 때문에 성능 향상을 기대할 수 있다.
database sharding
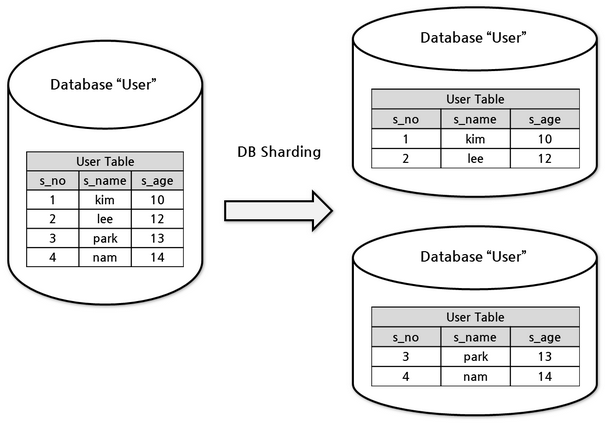
database sharding은 물리적으로 다른 데이터베이스에 데이터를 수평 분할(horizontal partitioning) 방식으로 분산 저장하고 조회하는 방법을 말한다. 예를 들어 'User Table'이 여러 데이터베이스에 있을 때 13세 미만의 유저를 0번 데이터베이스에 13세 이상의 유저를 1번 데이터베이스에 저장되도록 하는 방식이다. database sharding은 성능상 이유뿐 아니라 하나의 데이터베이스 인스턴스에 넣을 수 없는 큰 데이터를 분산하여 처리하기 위해 사용된다.
분할된 각 데이터베이스를 shard 또는 database shard라고 부른다.
CUBRID SHARD
CUBRID SHARD는 database sharding을 위한 미들웨어로, 다음과 같은 특징을 갖는다.
- 기존 응용의 변경을 최소화하기 위한 미들웨어 형태로서, 흔히 사용되는 JDBC(Java Database Connectivity)나 CUBRID C API인 CCI(CUBRID C Interface)를 이용하여 투명하게 sharding된 데이터에 접근할 수 있다.
- 힌트를 이용하여 실제 질의 수행할 shard를 선택하는 방식으로, 기존 사용하던 질의에 힌트를 추가하여 사용할 수 있다.
- 일부 트랜잭션의 특성을 보장한다.
CUBRID SHARD 기본 용어¶
다음은 앞으로 CUBRID SHARD를 설명하기 위해 사용되는 용어들로, 각 의미는 다음과 같다.
- shard DB : 분할된 테이블과 데이터를 포함하고 있으며, 실제로 사용자 요청을 처리하는 데이터베이스
- shard metadata : CUBRID SHARD의 동작을 위한 설정 정보. 요청된 질의를 분석하여 실제 질의를 수행할 shard DB를 선택하기 위한 정보 및 shard DB와의 데이터베이스 세션을 생성하기 위한 정보를 포함한다.
- shard key (column) : sharding된 테이블에서 shard를 선택하기 위한 식별자로 사용되는 칼럼
- shard key data : 질의 중 shard를 식별하기 위한 힌트에 해당하는 shard key의 값
- shard ID : shard DB를 식별하기 위한 식별자
- proxy : 사용자 질의에 포함된 힌트를 해석하고, 해석된 힌트와 shard metadata를 이용하여 실제 질의 처리할 shard DB로 요청을 전달하는 역할을 하는 CUBRID 미들웨어 프로세스
CUBRID SHARD 주요 기능¶
미들웨어 구조¶
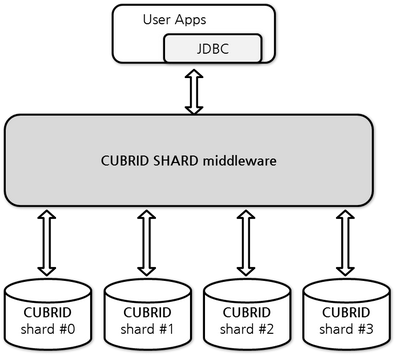
CUBRID SHARD는 응용 프로그램과 물리적 또는 논리적으로 분할된 shard의 중간에 위치하는 미들웨어(middleware)로서, 동시에 다수의 응용 프로그램과의 연결을 유지하며, 응용의 요청이 있는 경우 적절한 shard로 전달하여 처리하고 결과를 응용에 반환하는 기능을 수행한다.
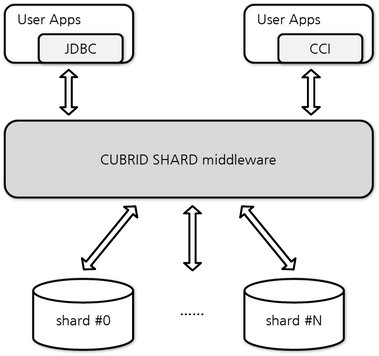
일반적으로 사용되는 JDBC(Java Database Connectivity)나 CUBRID C 인터페이스인 CCI(CUBRID C Interface)를 이용하여 CUBRID SHARD로 연결하여 응용의 요청을 처리할 수 있으며, 별도의 드라이버나 프레임워크가 필요 없기 때문에 기존 응용의 변경을 최소화할 수 있다.
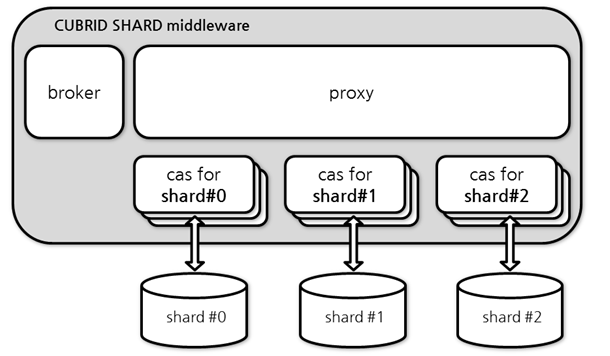
CUBRID SHARD middleware는 broker/proxy/CAS 세 개의 프로세스로 구성되며, 각 프로세스의 간략한 기능은 다음과 같다.
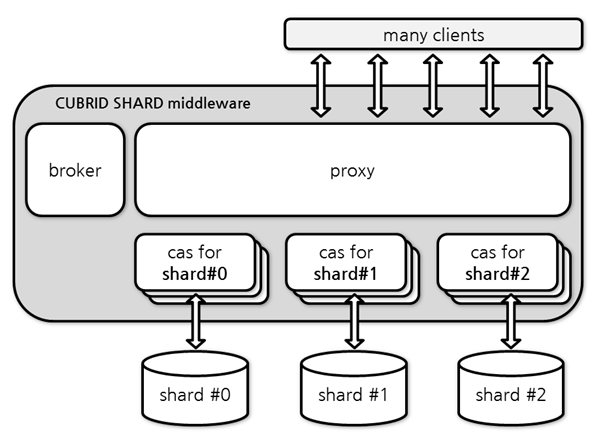
- broker
- JDBC/CCI 등 드라이버로부터의 최초 연결 요청을 수신하고, 수신된 연결 요청을 부하 분산 정책에 따라 proxy로 전달
- proxy 프로세스와 CAS 프로세스의 상태 감시 및 복구
- proxy
- 드라이버로부터의 사용자 요청을 CAS로 전달하고, 처리한 결과를 응용에 반환
- 드라이버 및 CAS와의 연결 상태 관리 및 트랜잭션 처리
- CAS
- 분할된 shard DB와 연결을 생성하고, 그 연결을 이용하여 proxy로부터 수신한 사용자 요청(질의)를 처리
- 트랜잭션 처리
shard SQL 힌트를 이용한 shard DB 선택¶
shard SQL 힌트
CUBRID SHARD는 SQL 힌트 구문에 포함된 힌트와 설정 정보를 이용하여, 응용으로부터 요청된 질의를 실제로 처리할 shard DB를 선택한다. 사용 가능한 SQL 힌트의 종류는 다음과 같다.
| SQL 힌트 | 설명 |
|---|---|
| /*+ shard_key */ | shard key 칼럼에 해당하는 바인드 변수 또는 리터럴 값의 위치를 지정하기 위한 힌트 |
| /*+ shard_val( value ) */ | 질의 내에 shard key에 해당하는 칼럼이 존재하지 않는 경우 힌트 내에 shard key를 명시적으로 지정하기 위한 힌트 |
| /*+ shard_id( shard_id ) */ | 사용자가 특정 shard DB를 지정하여 질의를 처리하고자 할 때 사용하는 힌트 |
설명을 위해 간략하게 용어를 정리하면 다음과 같다. 용어에 대한 보다 자세한 설명은 CUBRID SHARD 기본 용어를 참고한다.
- shard key : shard DB를 식별할 수 있는 칼럼. 일반적으로 shard DB 내의 모든 혹은 대부분의 테이블에 존재하는 칼럼으로서, DB 내에서 유일한 값을 갖는다.
- shard id : shard를 논리적으로 구분할 수 있는 식별자. 예를 들어, 하나의 DB가 4개의 shard DB로 분할되면 4개의 shard id가 존재한다.
힌트와 설정 정보를 이용한 자세한 질의 처리 절차는 shard SQL 힌트를 이용하여 질의가 수행되는 일반적인 절차를 참고한다.
Note
하나의 질의 안에 두 개 이상의 shard 힌트가 존재할 경우 서로 같은 shard를 가리키면 정상 처리하고, 다른 shard를 가리키면 오류 처리한다.
SELECT * FROM student WHERE shard_key = /*+ shard_key */ 250 OR shard_key = /*+ shard_key */ 22;
위와 같은 경우 250과 22가 같은 shard를 가리키면 정상 처리, 다른 shard를 가리키면 오류 처리한다.
여러 개의 값을 바인딩하는 배열로 질의를 일괄 처리하는 드라이버 함수(예: JDBC의 PreparedStatement.executeBatch, CCI의 cci_execute_array)에서 여러 개의 질의 중 하나라도 다른 shard에 접근하는 질의가 있으면 모두 오류 처리한다.
shard 환경에서 한번에 여러 문장을 실행하는 함수(예: JDBC의 Statement.executeBatch, CCI의 cci_execute_batch)는 추후 지원할 예정이다.
shard_key 힌트
shard_key 힌트는 바인드 변수나 리터럴 값의 위치를 지정하기 위한 힌트로서, 반드시 바인드 변수나 리터럴 값의 앞에 위치해야 한다.
예) 바인드 변수 위치 지정. 실행 시 바인딩되는 student_no 값에 해당하는 shard DB에서 질의를 수행.
SELECT name FROM student WHERE student_no = /*+ shard_key */ ?;
예) 리터럴 값 위치 지정. 실행 시 리터럴 값인 student_no가 123에 해당하는 shard DB에서 질의를 수행
SELECT name FROM student WHERE student_no = /*+ shard_key */ 123;
shard_val 힌트
shard_val 힌트는 질의 내에 shard DB를 식별할 수 있는 shard key 칼럼이 존재하지 않는 경우 사용하며, 실제 질의 처리 시 무시되는 shard key 칼럼을 shard_val 힌트의 값으로 설정한다. shard_val 힌트는 SQL 구문의 어느 곳에나 위치할 수 있다.
예) shard key가 student_no이나 질의 내에 포함되지 않은 경우. shard key인 student_no가 123에 해당하는 shard DB에서 질의를 수행
SELECT age FROM student WHERE name =? /*+ shard_val(123) */;
shard_id 힌트
shard_id 힌트는 shard key 칼럼의 값과 무관하게 사용자가 특정 shard를 지정하여 질의를 수행하고자 할 때 사용한다. shard_id 힌트는 SQL 구문의 어느 곳에나 위치할 수 있다.
예) shard DB #3 에서 질의를 수행해야 하는 경우. shard DB #3에서 age가 17보다 큰 학생을 조회
SELECT * FROM student WHERE age > 17 /*+ shard_id(3) */;
shard SQL 힌트를 이용하여 질의가 수행되는 일반적인 절차
질의 수행
다음은 사용자 질의 요청이 수행되는 과정이다.
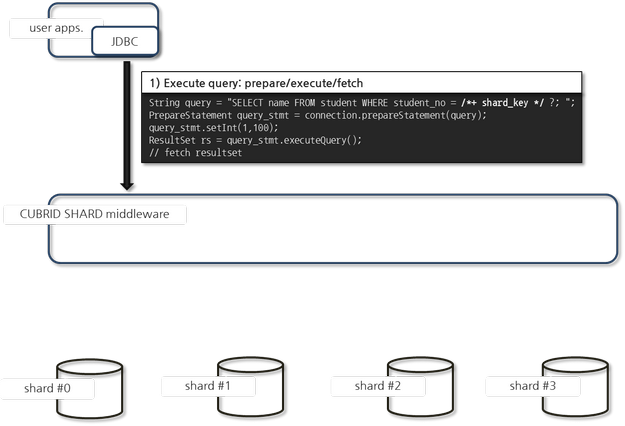
- 응용 프로그램은 JDBC 인터페이스를 통해 CUBRID SHARD로 질의 처리를 요청하며, 실제로 질의가 수행될 shard DB를 지정하기 위해 SQL 구문 내에 shard_key 힌트를 추가한다.
- SQL 힌트는 SQL 구문 내에서 위 예에서와 마찬가지로 shard key로 설정된 칼럼의 바인드 또는 리터럴 값 바로 앞에 위치해야 한다.
바인드 변수에 설정된 shard SQL 힌트는 다음과 같다.

리터럴 값에 지정된 shard SQL 힌트는 다음과 같다.

질의 분석 및 실제 요청을 처리할 shard DB 선택
질의를 분석하고 실제로 요청을 처리할 shard DB를 선택하는 과정은 다음과 같다.
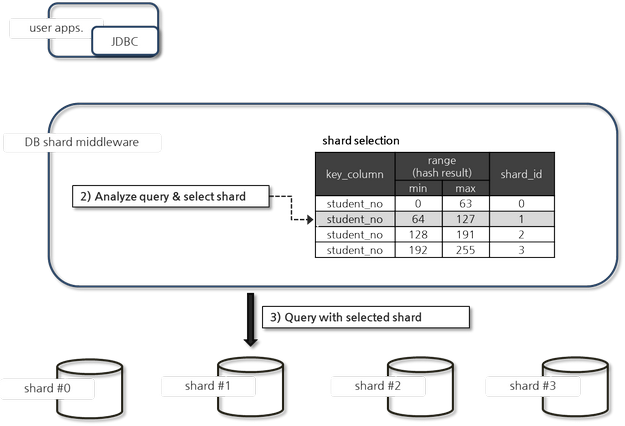
사용자로부터 수신한 SQL 질의를 내부에서 처리하기 위한 형태로 다시 작성된다(query rewrite).
사용자가 요청한 SQL 구문과 힌트를 이용하여 실제 질의를 수행한 shard DB를 선택한다.
바인드 변수에 SQL 힌트가 설정된 경우, execute 시 shard_key 바인드 변수에 대입된 값을 해시한 결과와 설정 정보를 이용하여 실제 질의가 수행될 shard DB를 선택한다.
해시 함수는 사용자가 별도로 지정할 수 있으며, 지정하지 않은 경우 기본 내장된 해시 함수를 이용하여 shard_key 값을 해싱한다. 기본 내장된 해시 함수는 다음과 같다.
shard_key가 정수인 경우
기본 해시 함수(shard_key) = shard_key mod SHARD_KEY_MODULAR 파라미터(기본값 256)
shard_key가 문자열인 경우
기본 해시 함수(shard_key) = shard_key[0] mod SHARD_KEY_MODULAR 파라미터(기본값 256)
Note
shard_key 바인드 변수의 값이 100인 경우, "기본 hash 함수(shard_key) = 100 % 256 = 100"이므로, 설정에 의해 해시 결과 100에 해당하는 shard DB #1이 선택되며, 선택된 shard DB #1으로 사용자 요청을 전달하게 된다.
질의 수행 결과 반환
질의 수행 결과를 반환하는 과정은 다음과 같다.
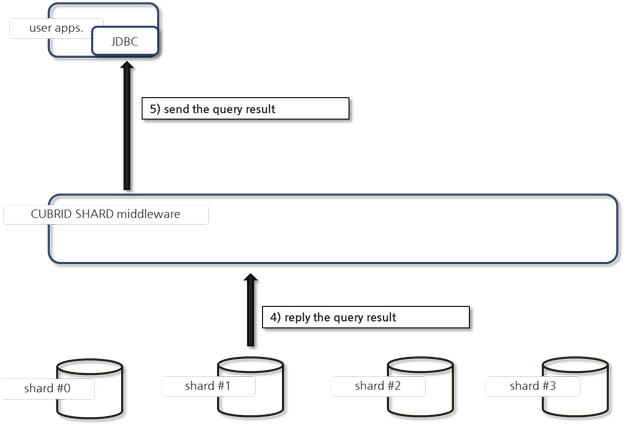
- shard DB #1 에서 수행한 처리 결과를 수신하여, 요청한 응용으로 결과를 반환한다.
Note
여러 개의 값을 바인딩하는 배열로 질의를 일괄 처리하는 드라이버 함수(예: JDBC의 executeBatch, CCI의 cci_execute_array, cci_execute_batch)에서 다른 shard에 접근하는 값이 존재하면 오류 처리한다.
트랜잭션 지원¶
트랜잭션 처리
CUBRID SHARD는 ACID 중 Atomicity(원자성)을 보장하기 위한 내부적인 처리 절차를 수행한다. 예를 들어, 트랜잭션 중 응용이 비정상 종료하는 등의 예외가 발생하면 해당 응용의 질의를 처리하던 shard DB로 롤백 요청을 전달하여 해당 트랜잭션 중 변경된 내용을 모두 무효화한다.
그 외 일반적인 트랜잭션의 특성인 ACID는 backend DBMS의 특성과 설정에 따라 보장된다.
제약 사항
2PC(2 Phase commit)는 불가능하며, 이 때문에 하나의 트랜잭션 중 여러 개의 shard DB로 질의를 수행하는 경우 에러 처리된다.
빠른 시작¶
구성 예¶
예로 설명될 CUBRID SHARD는 아래 그림과 같이 4개의 CUBRID SHARD DB로 구성되었으며, 응용은 JDBC 인터페이스를 사용하여 사용자 요청을 처리한다.
shard DB 및 사용자 계정 생성 후 시작
위 구성의 예와 같이 각 shard DB 노드에서 shard DB 및 사용자 계정을 생성한 후 데이터베이스를 인스턴스를 시작한다.
- shard DB 이름 : shard1
- shard DB 사용자 계정 : shard
- shard DB 사용자 비밀번호 : shard123
sh> # CUBRID SHARD DB 생성
sh> cubrid createdb shard1 en_US
sh> # CUBRID SHARD 사용자 계정 생성
sh> csql -S -u dba shard1 -c "create user shard password 'shard123'"
sh> # CUBRID SHARD DB 시작
sh> cubrid server start shard1
shard 설정 변경¶
cubrid_broker.conf
cubrid_broker.conf.shard를 참조하여 cubrid_broker.conf를 아래와 같이 변경한다.
Warning
포트 번호 및 공유 메모리 식별자는 현재 시스템에서 사용하지 않는 값으로 적절히 변경해야 한다.
[broker]
MASTER_SHM_ID =30001
ADMIN_LOG_FILE =log/broker/cubrid_broker.log
[%shard1]
SERVICE =ON
BROKER_PORT =36000
MIN_NUM_APPL_SERVER =20
MAX_NUM_APPL_SERVER =40
APPL_SERVER_SHM_ID =36000
LOG_DIR =log/broker/sql_log
ERROR_LOG_DIR =log/broker/error_log
SQL_LOG =ON
TIME_TO_KILL =120
SESSION_TIMEOUT =300
KEEP_CONNECTION =ON
MAX_PREPARED_STMT_COUNT =1024
SHARD =ON
SHARD_DB_NAME =shard1
SHARD_DB_USER =shard
SHARD_DB_PASSWORD =shard123
SHARD_NUM_PROXY =1
SHARD_PROXY_LOG_DIR =log/broker/proxy_log
SHARD_PROXY_LOG =ERROR
SHARD_MAX_CLIENTS =256
SHARD_PROXY_SHM_ID =36090
SHARD_CONNECTION_FILE =shard_connection.txt
SHARD_KEY_FILE =shard_key.txt
CUBRID의 경우 shard_connection.txt에 서버의 포트 번호를 별도로 설정하지 않고 cubrid.conf 설정 파일의 cubrid_port_id 파라미터를 사용하므로, cubrid.conf 의 cubrid_port_id 파라미터를 서버와 동일하게 설정한다.
# TCP port id for the CUBRID programs (used by all clients).
cubrid_port_id=41523
shard_key.txt
shard key 해시 값에 대한 shard DB 매핑 설정 파일인 shard_key.txt 파일을 아래와 같이 설정한다.
- [%shard_key] : shard key 섹션 설정
- 기본 해시 함수에 의한 shard key 해시 결과가 0~63인 경우 shard #0 에서 질의 수행
- 기본 해시 함수에 의한 shard key 해시 결과가 64~127인 경우 shard #1 에서 질의 수행
- 기본 해시 함수에 의한 shard key 해시 결과가 128~191인 경우 shard #2 에서 질의 수행
- 기본 해시 함수에 의한 shard key 해시 결과가 192~255인 경우 shard #3 에서 질의 수행
[%shard_key]
#min max shard_id
0 63 0
64 127 1
128 191 2
192 255 3
shard_connection.txt
shard 구성 데이터베이스 설정 파일인 shard_connection.txt 파일을 아래와 같이 설정한다.
- shard #0의 실제 데이터베이스 이름과 connection 정보
- shard #1의 실제 데이터베이스 이름과 connection 정보
- shard #2의 실제 데이터베이스 이름과 connection 정보
- shard #3의 실제 데이터베이스 이름과 connection 정보
# shard-id real-db-name connection-info
# * cubrid : hostname, hostname, ...
0 shard1 HostA
1 shard1 HostB
2 shard1 HostC
3 shard1 HostD
서비스 시작 및 모니터링¶
CUBRID SHARD 시작
CUBRID SHARD 기능을 사용하려면 아래와 같이 브로커를 구동한다.
sh> cubrid broker start
@ cubrid broker start
++ cubrid broker start: success
CUBRID SHARD 상태 조회
아래와 같이 CUBRID SHARD의 상태를 조회하여, 설정된 파라미터와 프로세스의 상태를 확인한다.
sh> cubrid broker status
@ cubrid broker status
% shard1
----------------------------------------------------------------
ID PID QPS LQS PSIZE STATUS
----------------------------------------------------------------
1-0-1 21272 0 0 53292 IDLE
1-1-1 21273 0 0 53292 IDLE
1-2-1 21274 0 0 53292 IDLE
1-3-1 21275 0 0 53292 IDLE
sh> cubrid broker status -f
@ cubrid broker status
% shard1
----------------------------------------------------------------------------------------------------------------------------------------------------------
ID PID QPS LQS PSIZE STATUS LAST ACCESS TIME DB HOST LAST CONNECT TIME SQL_LOG_MODE
----------------------------------------------------------------------------------------------------------------------------------------------------------
1-0-1 21272 0 0 53292 IDLE 2013/01/31 15:00:24 shard1@HostA HostA 2013/01/31 15:00:25 -
1-1-1 21273 0 0 53292 IDLE 2013/01/31 15:00:24 shard1@HostB HostB 2013/01/31 15:00:25 -
1-2-1 21274 0 0 53292 IDLE 2013/01/31 15:00:24 shard1@HostC HostC 2013/01/31 15:00:25 -
1-3-1 21275 0 0 53292 IDLE 2013/01/31 15:00:24 shard1@HostD HostD 2013/01/31 15:00:25 -
응용 예제 프로그램 작성¶
간단한 Java 프로그램을 이용하여 CUBRID SHARD 기능이 정상 동작함을 확인한다.
예제 테이블 생성
모든 shard DB에서 예제 프로그램을 위한 임시 테이블을 아래와 같이 생성한다.
sh> csql -C -u shard -p 'shard123' shard1@localhost -c "create table student (s_no int, s_name varchar, s_age int, primary key(s_no))"
예제 프로그램 작성
다음은 0~1023번의 학생 정보를 shard DB로 입력하는 예제 프로그램이다. 이전 절차에서 수정한 cubrid_broker.conf 를 확인하여 주소/포트 및 사용자 정보를 연결 URL에 설정한다.
import java.sql.DriverManager;
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.PreparedStatement;
import java.sql.Date;
import java.sql.*;
import cubrid.jdbc.driver.*;
public class TestInsert {
static {
try {
Class.forName("cubrid.jdbc.driver.CUBRIDDriver");
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
public static void DoTest(int thread_id) throws SQLException {
Connection connection = null;
try {
connection = DriverManager.getConnection("jdbc:cubrid:localhost:36000:shard1:::?charSet=utf8", "shard", "shard123");
connection.setAutoCommit(false);
for (int i=0; i < 1024; i++) {
String query = "INSERT INTO student VALUES (/*+ shard_key */ ?, ?, ?)";
PreparedStatement query_stmt = connection.prepareStatement(query);
String name="name_" + i;
query_stmt.setInt(1, i);
query_stmt.setString(2, name);
query_stmt.setInt(3, (i%64)+10);
query_stmt.executeUpdate();
System.out.print(".");
query_stmt.close();
connection.commit();
}
connection.close();
} catch(SQLException e) {
System.out.print("exception occurs : " + e.getErrorCode() + " - " + e.getMessage());
System.out.println();
connection.close();
}
}
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
try {
DoTest(1);
} catch(Exception e){
e.printStackTrace();
}
}
}
예제 프로그램 수행
위에서 작성한 예제 프로그램을 다음과 같이 수행한다.
sh> javac -cp ".:$CUBRID/jdbc/cubrid_jdbc.jar" *.java
sh> java -cp ".:$CUBRID/jdbc/cubrid_jdbc.jar" TestInsert
결과 확인
각 shard DB에서 질의를 수행하여 의도한 대로 분할된 정보가 정확하게 입력되었는지 확인한다.
shard #0
sh> csql -C -u shard -p 'shard123' shard1@localhost -c "select * from student order by s_no" s_no s_name s_age ================================================ 0 'name_0' 10 1 'name_1' 11 2 'name_2' 12 3 'name_3' 13 ...shard #1
sh> $ csql -C -u shard -p 'shard123' shard1@localhost -c "select * from student order by s_no" s_no s_name s_age ================================================ 64 'name_64' 10 65 'name_65' 11 66 'name_66' 12 67 'name_67' 13 ...shard #2
sh> $ csql -C -u shard -p 'shard123' shard1@localhost -c "select * from student order by s_no" s_no s_name s_age ================================================= 128 'name_128' 10 129 'name_129' 11 130 'name_130' 12 131 'name_131' 13 ...shard #3
sh> $ csql -C -u shard -p 'shard123' shard1@localhost -c "select * from student order by s_no" s_no s_name s_age ================================================ 192 'name_192' 10 193 'name_193' 11 194 'name_194' 12 195 'name_195' 13 ...
구성 및 설정¶
설정¶
CUBRID SHARD 기능을 사용하려면 cubrid_broker.conf 파일에서 SHARD 관련 프로세스들의 실행에 필요한 파라미터를 설정하고, shard 연결 파일(SHARD_CONNECTION_FILE)과 shard key 파일(SHARD_KEY_FILE)을 설정해야 한다.
cubrid_broker.conf¶
cubrid_broker.conf 는 CUBRID SHARD 기능을 설정할 때 사용한다. 설정 시 cubrid_broker.conf.shard를 참고하며, cubrid_broker.conf에 대한 자세한 내용은 브로커 설정을 참고한다.
shard 연결 파일(SHARD_CONNECTION_FILE)¶
CUBRID SHARD는 브로커 구동 시 cubrid_broker.conf의 SHARD_CONNECTION_FILE 파라미터에 지정된 shard 연결 설정 파일을 로딩하여 backend shard DB와의 연결을 수행한다.
설정 할 수 있는 shard DB 의 최대 개수는 256 개 이다.
cubrid_broker.conf에 SHARD_CONNECTION_FILE을 별도로 지정하지 않은 경우에는 기본값인 shard_connection.txt 파일을 로딩한다.
기본 형식
shard 연결 설정 파일의 기본적인 예와 형식은 아래와 같다.
#
# shard-id real-db-name connection-info
# * cubrid : hostname, hostname, ...
# CUBRID
0 shard1 HostA
1 shard1 HostB
2 shard1 HostC
3 shard1 HostD
Note
일반적인 CUBRID 설정과 마찬가지로 # 이후 내용은 주석으로 처리된다.
CUBRID
backend shard DB가 CUBRID인 경우 연결 설정 파일의 형식은 다음과 같다.
# CUBRID
# shard-id real-db-name connection-info
# shard 식별자( >0 ) 각 backend shard DB 의 실제 이름 호스트 이름
0 shard_db_1 host1
1 shard_db_2 host2
2 shard_db_3 host3
3 shard_db_4 host4
CUBRID의 경우 별도의 backend shard DB의 포트 번호를 위 설정 파일에 지정하지 않고, cubrid.conf의 CUBRID_PORT_ID 파라미터를 사용한다. cubrid.conf 파일은 기본적으로 $CUBRID/conf 디렉터리에 위치한다.
$ vi cubrid.conf
...
# TCP port id for the CUBRID programs (used by all clients).
cubrid_port_id=41523
shard key 파일(SHARD_KEY_FILE)¶
CUBRID SHARD는 시작 시 기본 설정 파일인 cubrid_broker.conf 의 SHARD_KEY_FILE 파라미터에 지정된 shard key 설정 파일을 로딩하여 사용자 요청을 어떤 backend shard DB에서 처리해야 할지 결정하는 데 사용한다.
cubrid_broker.conf 에 SHARD_KEY_FILE 을 별도로 지정하지 않은 경우에는 기본값인 shard_key.txt 파일을 로딩한다.
형식
shard key 설정 파일의 예와 형식은 다음과 같다.
[%student_no]
#min max shard_id
0 31 0
32 63 1
64 95 2
96 127 3
128 159 0
160 191 1
192 223 2
224 255 3
- [%shard_key_name] : shard key의 이름을 지정
- min : shard key 해시 결과의 최소값 범위
- max : shard key 해시 결과의 최대 범위
- shard_id : shard 식별자
Note
일반적인 CUBRID 설정과 마찬가지로 # 이후 내용은 주석으로 처리된다.
Warning
- shard key의 min은 항상 0부터 시작해야 한다.
- max는 최대 255까지 설정해야 한다.
- min~max 사이에는 빈 값이 존재하면 안 된다.
- 내장 해시 함수를 사용하는 경우 SHARD_KEY_MODULAR 파라미터 값(최소 1, 최대 256)을 초과할 수 없다.
- shard key 해시 결과는 0 ~ (SHARD_KEY_MODULAR - 1)의 범위에 반드시 포함되어야 한다.
사용자 정의 해시 함수¶
CUBRID SHARD는 질의를 수행할 shard를 선택하기 위해 shard key를 해싱한 결과와 메타데이터 설정 정보를 이용한다. 이를 위해 기본 내장된 해시 함수를 사용하거나, 또는 사용자가 별도로 해시 함수를 정의할 수 있다.
내장된 기본 해시 함수
cubrid_broker.conf 의 SHARD_KEY_LIBRARY_NAME, SHARD_KEY_FUNCTION_NAME 파라미터를 설정하지 않는 경우 기본 내장된 해시 함수를 이용하여 shard key를 해시하며, 기본 해시 함수의 내용은 아래와 같다.
shard_key가 정수인 경우
기본 해시 함수(shard_key) = shard_key mod SHARD_KEY_MODULAR 파라미터(기본값 256)
shard_key가 문자열인 경우
기본 해시 함수(shard_key) = shard_key[0] mod SHARD_KEY_MODULAR 파라미터(기본값 256)
사용자 해시 함수 설정
CUBRID SHARD는 기본 내장된 해시 함수 외에 사용자 정의 해시 함수를 이용하여 질의에 포함된 shard key를 해싱할 수 있다.
라이브러리 구현 및 생성
사용자 정의 해시 함수는 실행 시간에 로딩 가능한 .so 형태의 라이브러리로 구현되어야 하며 프로토타입은 아래와 같다.
/* return value : success - shard key id(>0) fail - invalid argument(ERROR_ON_ARGUMENT), shard key id make fail(ERROR_ON_MAKE_SHARD_KEY) type : shard key value type val : shard key value */ typedef int (*FN_GET_SHARD_KEY) (const char *shard_key, T_SHARD_U_TYPE type, const void *val, int val_size);
- 해시 함수의 반환 값은 shard_key.txt 설정 파일의 해시 결과 범위에 반드시 포함되어야 한다.
- 라이브러리를 빌드하기 위해서는 반드시 $CUBRID/include/shard_key.h 파일을 include해야 한다. 이 파일에서 반환 가능한 에러 코드 등 자세한 내용도 확인할 수 있다.
cubrid_broker.conf 설정 파일 변경
생성한 사용자 정의 해시 함수를 반영하기 위해서는 cubrid_broker.conf의 SHARD_KEY_LIBRARY_NAME, SHARD_KEY_FUNCTION_NAME 파라미터를 구현 내용에 맞도록 설정해야 한다.
- SHARD_KEY_LIBRARY_NAME : 사용자 정의 해시 라이브러리의 (절대) 경로
- SHARD_KEY_FUNCTION_NAME : 사용자 정의 해시 함수의 이름
예제
다음은 사용자 정의 해시 함수를 사용한 예이다. 먼저 shard_key.txt 설정 파일을 확인한다.
[%student_no] #min max shard_id 0 31 0 32 63 1 64 95 2 96 127 3 128 159 0 160 191 1 192 223 2 224 255 3사용자 지정 해시 함수를 설정하기 위해서는 실행 시간에 로딩 가능한 .so 형태의 공유 라이브러리를 먼저 구현해야 한다. 해시 함수의 결과는 이전 과정에서 확인한 shard_key.txt 설정 파일에 정의된 해시 결과의 범위 안에 포함되는 값이어야 한다. 다음은 간단한 구현 예이다.
- shard_key가 정수인 경우
- shard_key가 홀수인 경우 shard #0을 선택
- shard_key가 짝수인 경우 shard #1을 선택
- shard_key가 문자열인 경우
- shard_key 문자열이 'a', 'A'로 시작되는 경우 shard #0을 선택
- shard_key 문자열이 'b', 'B'로 시작되는 경우 shard #1을 선택
- shard_key 문자열이 'c', 'C'로 시작되는 경우 shard #2를 선택
- shard_key 문자열이 'd', 'D'로 시작되는 경우 shard #3을 선택
// <shard_key_udf.c> #include <string.h> #include <stdio.h> #include <unistd.h> #include "shard_key.h" int fn_shard_key_udf (const char *shard_key, T_SHARD_U_TYPE type, const void *value, int value_len) { unsigned int ival; unsigned char c; if (value == NULL) { return ERROR_ON_ARGUMENT; } switch (type) { case SHARD_U_TYPE_INT: ival = (unsigned int) (*(unsigned int *) value); if (ival % 2) { return 32; // shard #1 } else { return 0; // shard #0 } break; case SHARD_U_TYPE_STRING: c = (unsigned char) (((unsigned char *) value)[0]); switch (c) { case 'a': case 'A': return 0; // shard #0 case 'b': case 'B': return 32; // shard #1 case 'c': case 'C': return 64; // shard #2 case 'd': case 'D': return 96; // shard #3 default: return ERROR_ON_ARGUMENT; } break; default: return ERROR_ON_ARGUMENT; } return ERROR_ON_MAKE_SHARD_KEY; }사용자 지정 해시 함수를 공유 라이브러리 형태로 빌드한다. 다음은 해시 함수 빌드를 위한 Makefile의 예이다.
# Makefile CC = gcc LIBS = $(LIB_FLAG) CFLAGS = $(CFLAGS_COMMON) -fPIC -I$(CUBRID)/include -I$(CUBRID_SRC)/src/broker SHARD_CC = gcc -g -shared -Wl,-soname,shard_key_udf.so SHARD_KEY_UDF_OBJS = shard_key_udf.o all:$(SHARD_KEY_UDF_OBJS) $(SHARD_CC) $(CFLAGS) -o shard_key_udf.so $(SHARD_KEY_UDF_OBJS) $(LIBS) clean: -rm -f *.o core shard_key_udf.so사용자 정의 해시 함수를 포함하기 위해 SHARD_KEY_LIBRARY_NAME, SHARD_KEY_FUNCTION_NAME 파라미터를 위 구현과 일치하도록 수정한다.
[%student_no] SHARD_KEY_LIBRARY_NAME =$CUBRID/conf/shard_key_udf.so SHARD_KEY_FUNCTION_NAME =fn_shard_key_udfNote
- 응용 프로그램에서 사용자 해시 함수를 정의할 때 shard key의 입력 값으로 16bit(short), 32bit(int), 64bit(INT64) integer를 사용할 수 있다.
- VARCHAR를 사용해야 되는 경우 사용자가 해시 함수를 정의해야 한다.
구동 및 모니터링¶
cubrid broker 유틸리티를 이용하여 CUBRID SHARD 기능을 구동하거나 정지할 수 있고, 각종 상태 정보를 조회할 수 있다. 보다 자세한 내용은 브로커를 참고한다.
CUBRID SHARD 로그¶
SHARD 구동과 관련된 로그에는 접속 로그, 프록시 로그, SQL 로그, 에러 로그가 있다. 각각 로그의 저장 디렉터리 변경은 SHARD 환경 설정 파일(cubrid_broker.conf) 의 LOG_DIR, ERROR_LOG_DIR, PROXY_LOG_DIR 파라미터를 통해 설정할 수 있다.
SHARD PROXY 로그¶
접속 로그
- 파라미터: ACCESS_LOG
- 설명: 클라이언트의 접속을 logging한다(기존 브로커는 CAS에서 로그를 남긴다).
- 기본 저장 디렉터리: $CUBRID/log/broker/
- 파일 이름: <broker_name>_<proxy_index>.access
- 로그 형식: CAS에서 남기는 access log와 cas_index 이외의 모든 string 동일
10.24.18.67 - - 1340243427.828 1340243427.828 2012/06/21 10:50:27 ~ 2012/06/21 10:50:27 23377 - -1 shard1 shard1
10.24.18.67 - - 1340243427.858 1340243427.858 2012/06/21 10:50:27 ~ 2012/06/21 10:50:27 23377 - -1 shard1 shard1
10.24.18.67 - - 1340243446.791 1340243446.791 2012/06/21 10:50:46 ~ 2012/06/21 10:50:46 23377 - -1 shard1 shard1
10.24.18.67 - - 1340243446.821 1340243446.821 2012/06/21 10:50:46 ~ 2012/06/21 10:50:46 23377 - -1 shard1 shard1
프록시 로그
- 파라미터: SHARD_PROXY_LOG_DIR
- 설명: proxy 내부의 동작을 logging한다.
- 기본 저장 디렉터리: $CUBRID/log/broker/proxy_log
- 파일 이름: <broker_name>_<proxy_index>.log
06/21 10:50:46.822 [SRD] ../../src/broker/shard_proxy_io.c(1045): New socket io created. (fd:50).
06/21 10:50:46.822 [SRD] ../../src/broker/shard_proxy_io.c(2517): New client connected. client(client_id:3, is_busy:Y, fd:50, ctx_cid:3, ctx_uid:4).
06/21 10:50:46.825 [DBG] ../../src/broker/shard_proxy_io.c(3298): Shard status. (num_cas_in_tran=1, shard_id=2).
06/21 10:50:46.827 [DBG] ../../src/broker/shard_proxy_io.c(3385): Shard status. (num_cas_in_tran=0, shard_id=2).
프록시 로그 레벨
- 파라미터: SHARD_PROXY_LOG
- 프록시 로그 레벨 정책: 상위 level을 설정하면 하위의 모든 로그가 남는다.
- 예) SCHEDULE을 설정하면, ERROR | TIMEOUT | NOTICE | SHARD | SCHEDULE 로그를 모두 남긴다.
- 프록시 로그 레벨 항목
- NONE or OFF: 로그를 남기지 않는다.
- ERROR(default): 내부적으로 에러가 발생하여 정상적으로 처리되지 못하는 경우
- TIMEOUT: session timeout이나 query timeout 등의 timeout
- NOTICE: 힌트 없는 query 및 기타 에러는 아닌 경우
- SHARD: client 의 request가 어떤 shard의 어떤 CAS로 갔는지, 그것이 다시 client response 되었는지 등의 scheduling
- SCHEDULE: 힌트 parsing 및 hash를 통해 shard key id 가져오는 것 등의 shard processing
- ALL: 모든 로그
SHARD CAS 로그¶
SQL 로그
- 파라미터 : SQL_LOG
- 설명 : prepare/execute/fetch 등의 query 및 기타 CAS 정보를 logging한다.
- 기본 저장 디렉터리 : $CUBRID/log/broker/sql_log
- 파일 이름 : <broker_name>_<proxy_index>_<shard_index>_<cas_index>.sql.log
13-06-21 10:13:00.005 (0) STATE idle
13-06-21 10:13:01.035 (0) CAS TERMINATED pid 31595
13-06-21 10:14:20.198 (0) CAS STARTED pid 23378
13-06-21 10:14:21.227 (0) connect db shard1@HostA user dba url shard1 session id 3
13-06-21 10:14:21.227 (0) DEFAULT isolation_level 3, lock_timeout -1
13-06-21 10:50:28.259 (1) prepare srv_h_id 1
13-06-21 10:50:28.259 (0) auto_rollback
13-06-21 10:50:28.259 (0) auto_rollback 0
에러 로그
- 파라미터 : ERROR_LOG_DIR
- 설명 : CUBRID의 경우 cs library에서 EID 및 error string을 해당 파일에 logging한다.
- 기본 저장 디렉터리 : $CUBRID/log/broker/error_log
- 파일 이름 : <broker_name>_<proxy_index>_<shard_index>_<cas_index>.err
Time: 06/21/13 10:50:27.776 - DEBUG *** file ../../src/transaction/boot_cl.c, line 1409
trying to connect 'shard1@localhost'
Time: 06/21/13 10:50:27.776 - DEBUG *** file ../../src/transaction/boot_cl.c, line 1418
ping server with handshake
Time: 06/21/13 10:50:27.777 - DEBUG *** file ../../src/transaction/boot_cl.c, line 966
boot_restart_client: register client { type 4 db shard1 user dba password (null) program cubrid_cub_cas_1 login cubrid_user host HostA pid 23270 }
제약 사항¶
Linux만 지원
Linux에서만 CUBRID SHARD 기능을 사용할 수 있다.
하나의 트랜잭션은 하나의 shard DB에서만 수행 가능
하나의 트랜잭션은 오직 하나의 shard DB에서만 수행되어야 하며, 따라서 아래와 같은 제약사항이 존재한다.
- shard key 변경(UPDATE)으로 인해 여러 shard DB의 데이터를 변경하는 것은 불가능하며, 필요하다면 DELETE / INSERT 를 이용한다.
- 2개 이상의 샤드에 대한 질의(join, sub-query, or, union, group by, between, like, in, exist, any/some/all 등)를 지원하지 않는다.
세션 정보는 각 shard DB 내에서만 유효
세션 정보가 각 shard DB 내에서만 유효하므로, LAST_INSERT_ID()와 같은 세션 관련 함수의 결과가 의도한 바와 다를 수 있다.
SET NAMES 문 지원 안 함
SHARD 구성 환경에서는 SET NAMES 문이 정상 동작하지 않을 수 있으므로, 사용을 권장하지 않는다.
auto increment는 각 shard DB 내에서만 유효
auto increment 속성 또는 SERIAL 등의 값이 각 shard DB 내에서만 유효하므로, 의도한 것과 다른 값을 반환할 수 있다.